
Bringing Personalized Search to Etsy


The Etsy marketplace brings together shoppers and independent sellers from all over the world. Our unconventional inventory presents unique challenges for product search, given that many of our listings fall outside of standard e-commerce categories. With more than 80 million listings and 3.7 million sellers, Etsy relies on machine learning to help users browse creative, handmade goods in their search results. But what if we could make the search experience even better with results tailored to each user? Enter personalized search results.
Search results for "tray"
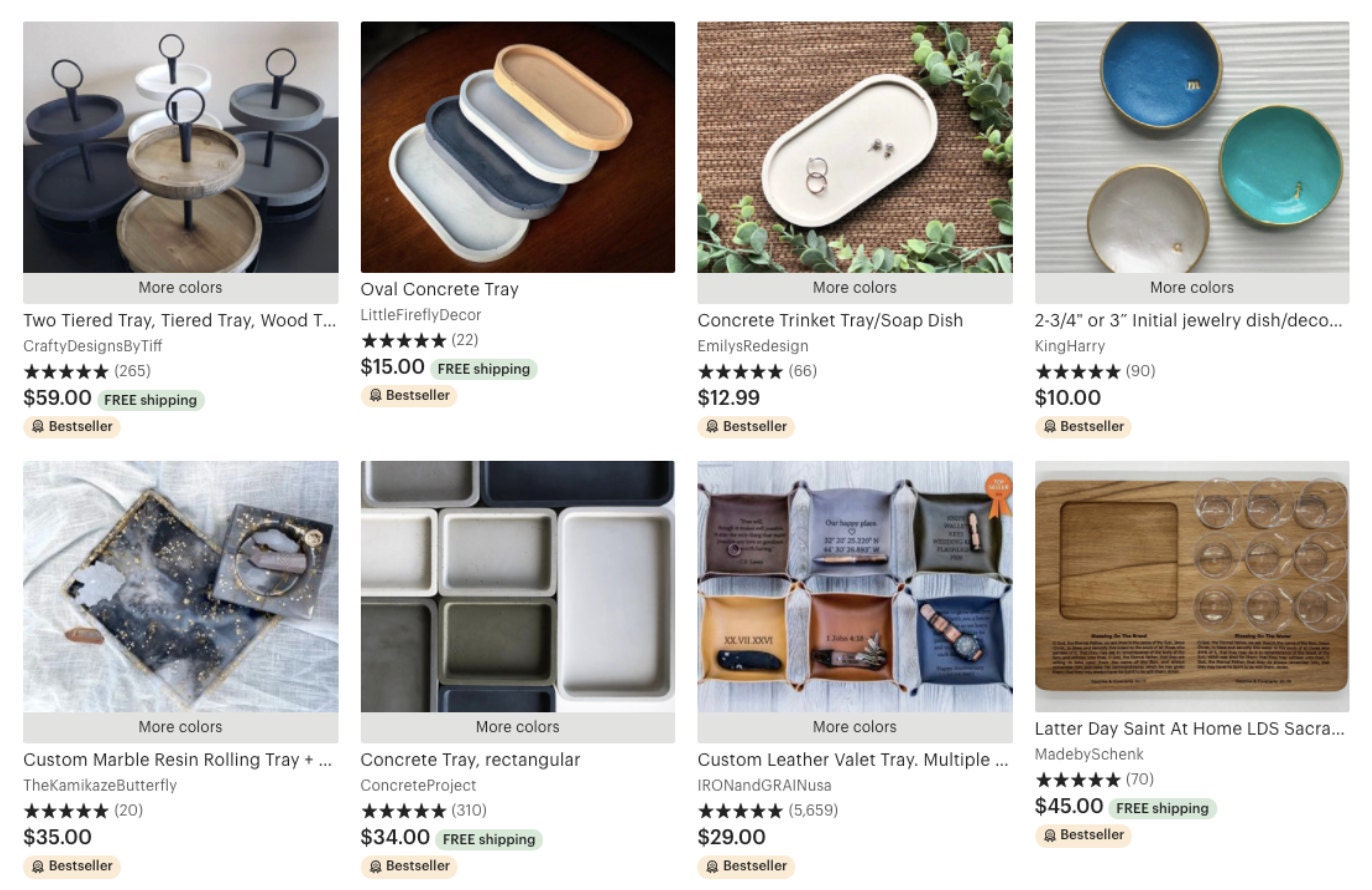
(above) default results, (below) a user who recently interacted with leather goods
When a user logs into the marketplace and searches for items, they signal their preferences by interacting with listings that pique their interest. In personalization, our algorithms train on these signals and learn to predict, per user, the most relevant listings. The resulting personalized model lets individuals' taste shine through in their search results without compromising performance. Personalization enhances the underlying search model by customizing the ordering of relevant items according to user preference. Using a combination of historical and contextual features, the search ranking model learns to recognize which items have a greater alignment with an individual's taste.
In the following sections, we describe the Etsy search architecture and pipeline, the features we use to create personalized search results, and the performance of this new model. Finally, we reflect on the challenges from launching our first personalized search model and look ahead to future iterations of personalization. Please note that some sections of the post are more technical and assume knowledge of machine learning basics from the reader.
Etsy Search Architecture
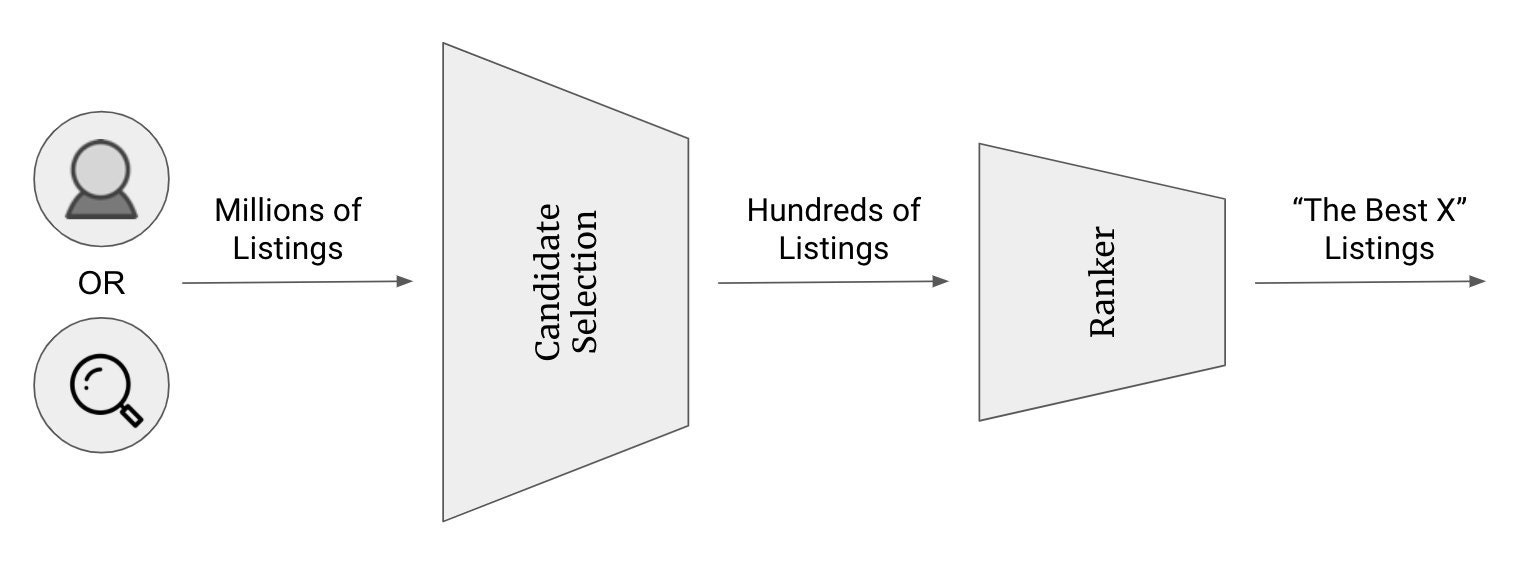
The search pipeline is separated into two passes: candidate set retrieval and ranking. This ensures that we are returning low-latency results -- a crucial component of a good search system. Because the latter ranking step is computationally expensive, we want to use it wisely. So from millions of total listings, the candidate set retrieval step selects the top one thousand items for a query by considering tags, titles, and other seller-provided attributes. This allows us to run the ranking algorithm over less than one percent of all listings. In the end, the ranker will place the most relevant items at the top of the search results page.
Our search ranking algorithm is an ensemble model that uses a gradient boosted decision tree with pairwise formulation. For personalization, we introduce a new set of features that allow us to model user preferences. These features are included in addition to existing features, such as listing price and recency. And as much as we try to avoid impacting latency, the introduction of these personalized features creates new challenges in serving online results. Because the features are specific to each user, the cache utilization rate drops. We address this and other challenges in a later section.
Personalized User Representations
The novelty of personalized search results lies in the new features we pass to the ranker. We categorize personalization features into two groups: historical and contextual features.
Historical features refer to singular data points about a user's profile that can succinctly describe shopping habits and behaviors. Are they modern consumers of digital goods, or are they hunting and gathering vintage pieces? Do they carefully deliberate on each individual purchase, or do they follow their lightning-strike gut instinct? We can gather these insights from the number of digital or vintage items purchased and average number of site visits. Historical user features help us put the "person" in personalization.
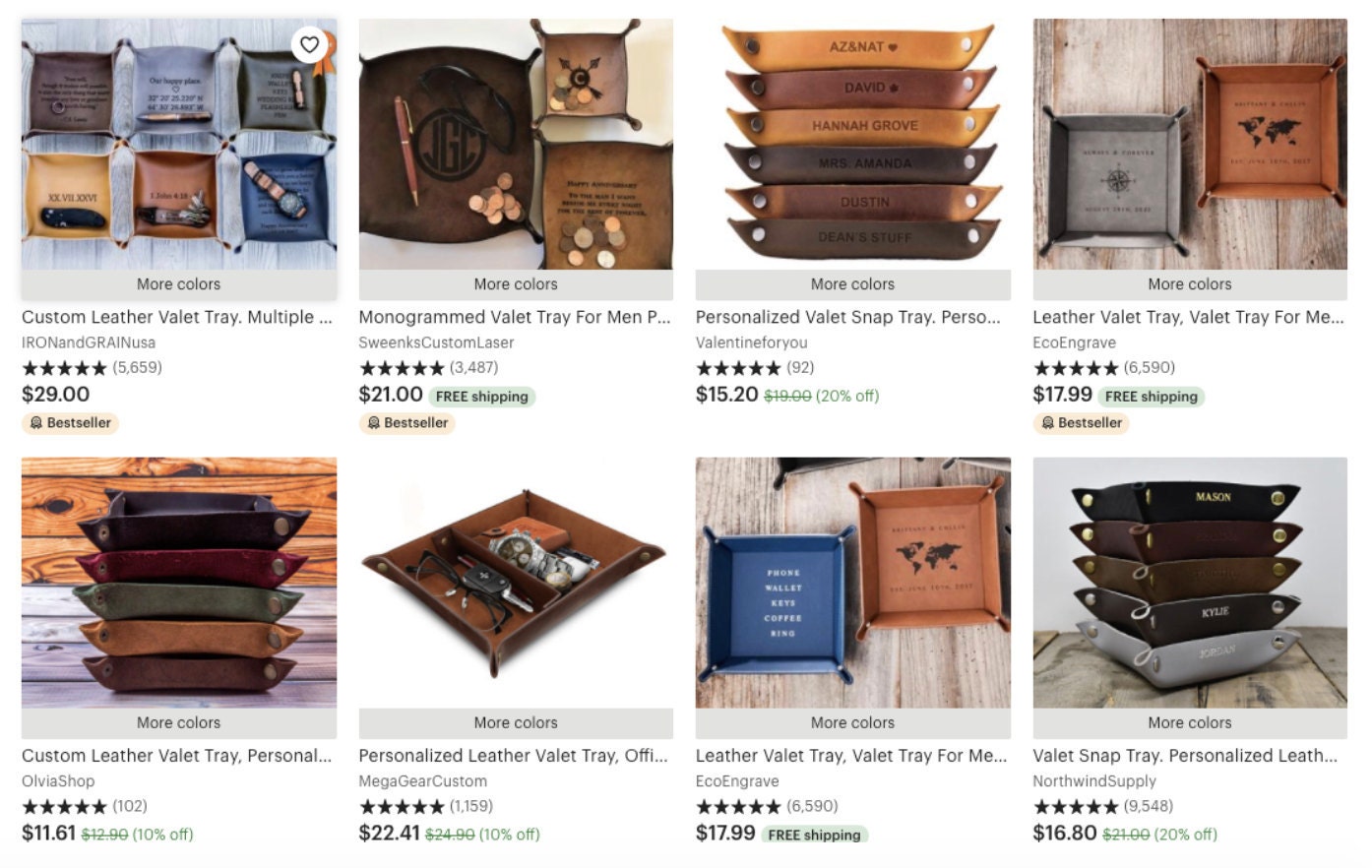
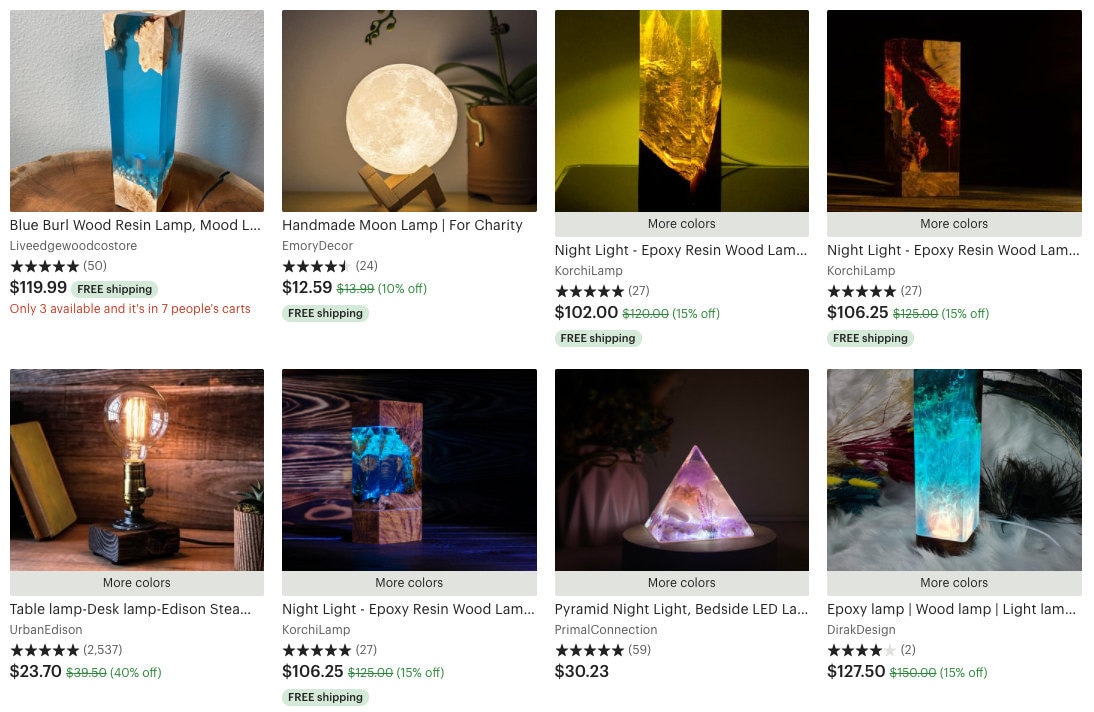
Search results for "lamp"
(above) default results, (below) a user who recently interacted with epoxy resin items
In contrast to these numerical features, data can also be represented as a vector, or a list of numbers. For personalization, we refer to these vectored features as contextual features because the listing vector represents a listing with respect to the context of all other listings. In fact, there are many ways to represent a listing as a vector but we use term frequency–inverse document frequency (Tf-Idf), item-interaction embeddings and interaction-based graph embeddings. If you're unfamiliar with any of these methods, don't worry! We'll be diving deeper into the specific vector generation algorithms.
So how do we capture a user's preferences from a bunch of listing vectors? One method is to average all the listings a user has clicked on to represent them. In other words, the user contextual vector is simply the average of all the interacted listings' contextual vectors.
We gather historical and contextual features from across our mobile web, desktop and mobile application platforms. This allows us to maximize the amount of information our model can use to personalize search result rankings.
The Many Ways Users Show Us Love
In addition to clicks on a listing from search results, a user has a few other ways to connect with sellers' items on the marketplace. After a user searches for an item, they can favorite items in the search results page and save them to their own curated collections, they can add an item to their cart while they continue to browse, and once they are satisfied with their selection they can purchase the item.
Each of these interactions has distinct characteristics which help our model generalize and generate more accurate predictions. Clicks are by far the most popular way for buyers to engage with listings, and through sheer quantity provide for a rich source of material to model user behaviors. On the other end, purchase interactions occur less frequently than clicks but contain stronger indications of relevance of an item to the user's search query.
The Heart of Personalization
Now, let's get to the crux of personalization and dig deeper into user contextual features.
Tf-Idf vectors consider listings from a textual standpoint, where words in the seller-provided attributes are weighted according to their importance. These attributes include listing titles, tags, and others. Each word's importance is derived with respect to its frequency in the immediate listing text, but also the larger corpus of listing texts. This allows us to distinguish a listing from others and capture its unique qualities. When we average the last few months' worth of listings a user has interacted with, we are averaging the weights of words in those listings to create a single Tf-Idf vector and represent the user. In other words, in Tf-Idf a listing is represented by its most important listing words and a user is represented as an average of those most important words.
Diagram of interaction-based graph embedding
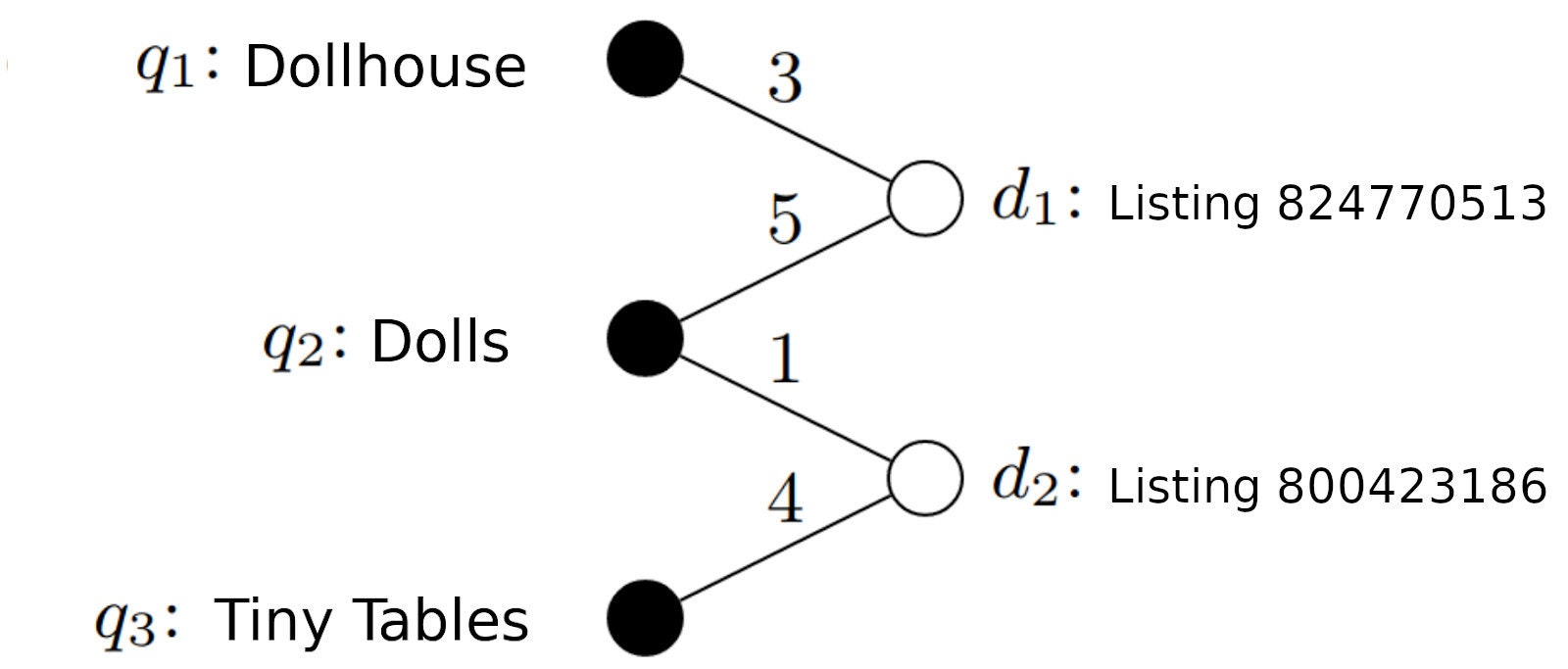
In this example of interaction-based graph embeddings, the queries "dollhouse" and "dolls" resulted in clicks on listing 824770513 on three and five occasions, respectively.
Unlike Tf-Idf, an interaction-based graph embedding can capture the larger interaction context of query and listing journeys. Recall that interactions can be as clicks, favorites, add-to-carts or purchases from a user. Let's say we have a query and some listings that are often clicked with that query. When we match words within the query to the words in the listing texts and weigh the words common to both of them, we can represent listings and queries with the same vocabulary. A common vocabulary is an important quality in textual representations because we can derive degrees of relatedness between queries to listings despite differences in length and purpose. Therefore, if a few different listings are all clicked as a result of the same query, we expect the embeddings for these listings to be similar.
And similar to Tf-Idf, we can simply average the weights of words in the sparse vectors over some time frame. Whereas graph embeddings weave behavior from interaction logs into the vector representation, Tf-Idf only uses available listing text. Put more plainly, for graph embeddings users tell us which queries and listings are related and we model this information by finding overlaps between their words.
Diagram from Learning Item-Interaction Embeddings for User Recommendations

However, focusing on a single interaction type within an embedding can be limiting. In reality, users can have a combination of different interactions within a single shopping session. Item-interaction vectors can learn multiple interactions in the same space. Created by our very own data scientists here at Etsy, item-interaction vectors build upon the methods of word2vec where words occurring in the same context share a higher vector similarity.
The implementation of item-interaction vectors is simple but elegant: we replace words and sentences with item-interaction token pairs and sequences of interacted items. A token pair is formulated as (item, interaction-type) to represent how a user interacted with a specific item or listing. And an ordered list of these tokens represents the sequence of what and how a user interacted with various listings in a session. As a result, item-interaction token pairs that appear in the same context will be considered similar.
Because these listings embeddings are dense vectors, we can easily find similar listings via distance metrics. To summarize item-interaction vectors, similar to interaction-based graph embeddings we let the users guide us in learning which listings are similar. But rather than deriving listing similarities from query and listing relationships, we infer similarity if listings appear in the same sequences of interactions.
Putting It All Together
Let's take stock of what we have to work with: recent or lifetime look back windows, three types of contextual features (Tf-Idf, graph embedding, item-interaction), and four types of user behavior interactions (click, favorite, add-to-cart, purchase). Mixing and matching these together, we have a grand total of 24 contextual vectors to represent a single user in order to rank items for personalized search results. For example, we can combine an overall time window, item-interaction method, and "favorite" interactions to generate an item-interaction vector that represents a user's all-time favorite listings.
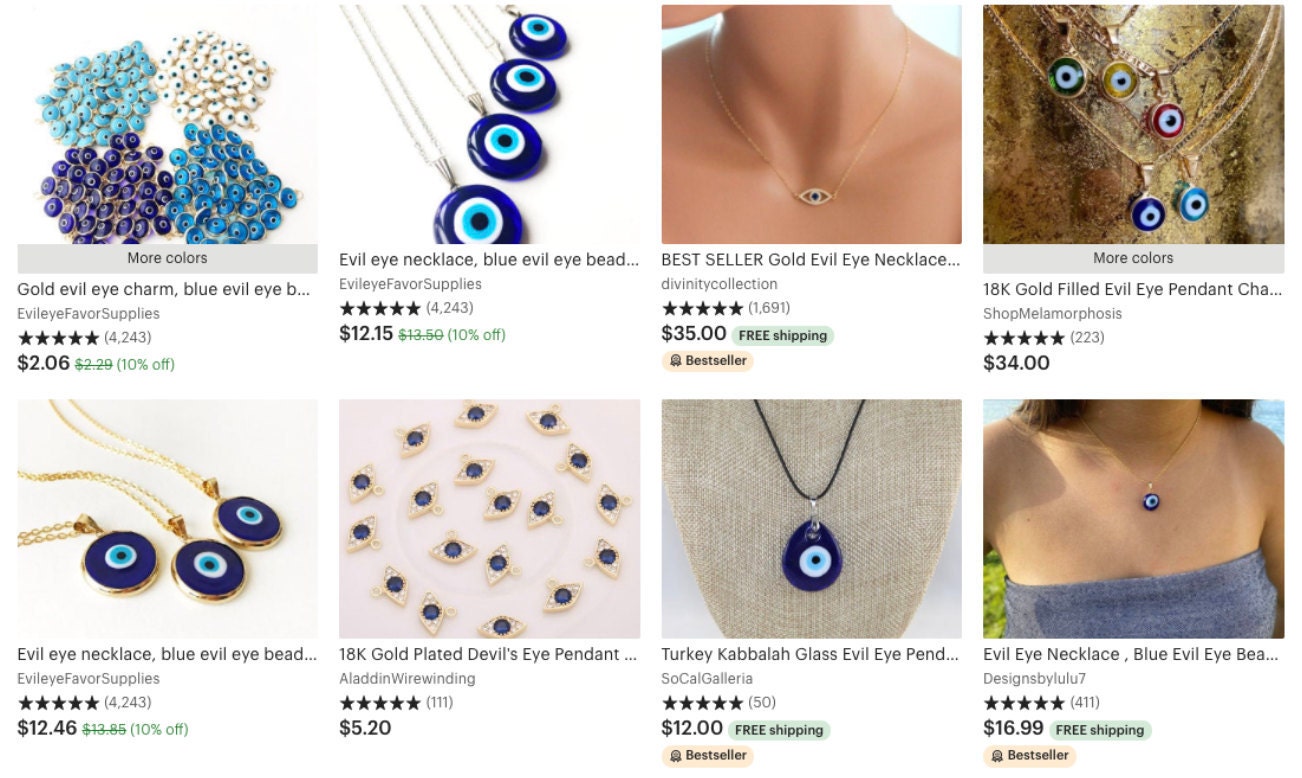
Search results for "necklace charms blue"
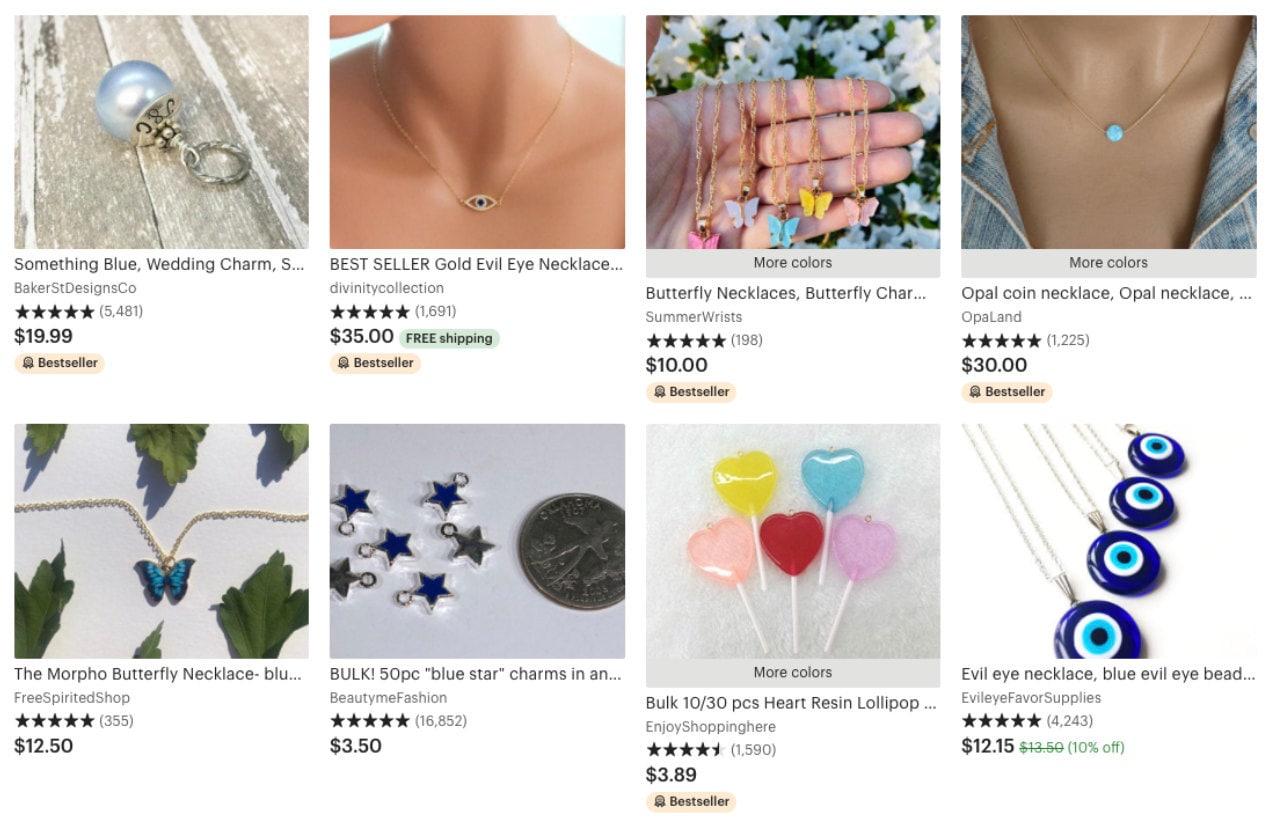
(above) default results, (below) a user who recently interacted with eye charms
In personalized search ranking, when a user enters a query we still do a coarse sweep of the inventory and grab top-related items to a query in candidate set retrieval. But in the ranking of items, we now include our new features. Recall that decision trees take input features in the form of integers or decimals.
To satisfy this requirement, we can pass user historical features straight through to the tree or create new features by combining them with other features beforehand. To include user contextual features in the ranking, we have to compute similarity metrics between users' contextual vectors and the candidate listing vectors from the candidate retrieval step. We derive Jaccard similarity and token overlap for sparse vectors and cosine similarity for dense vectors. From these metrics we understand which candidate listings are more similar to listings a user has previously interacted with. However, this metric alone is not sufficient to determine a final ranking.
Decision trees take these inputs and learn how each feature impacts whether an item will be purchased. We feed user historical features, similarity measures, and other non-personalized features into the tree so it can learn to rank listings from most relevant to least. The expectation is that the most relevant listings are the items a user is more likely to purchase.
Personalized Search Performance
In online A/B experiments we compared this personalized model with a control and observed an improvement in ranking performance from a purchase’s normalized discounted cumulative gain (NDCG). NDCG captures the goodness of a ranking. If, on average, users purchase items ranked higher on the page, this ranking would have a high purchase NDCG. In our experiments, we observed that the NDCG for personalization was especially high for users that have recently and/or often interacted with the marketplace.
Search results for "print maxi dress"
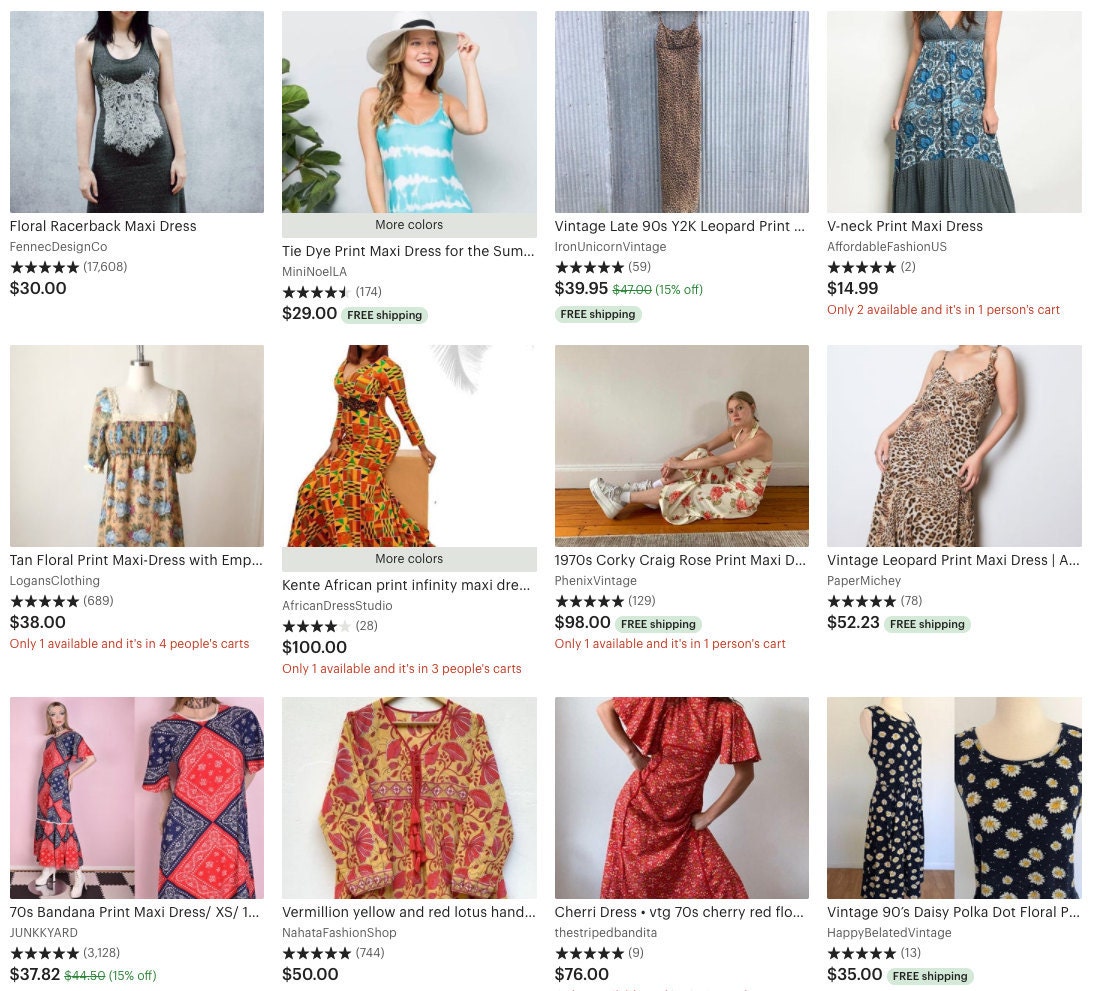
(above) default results, (below) a user who recently interacted with African prints
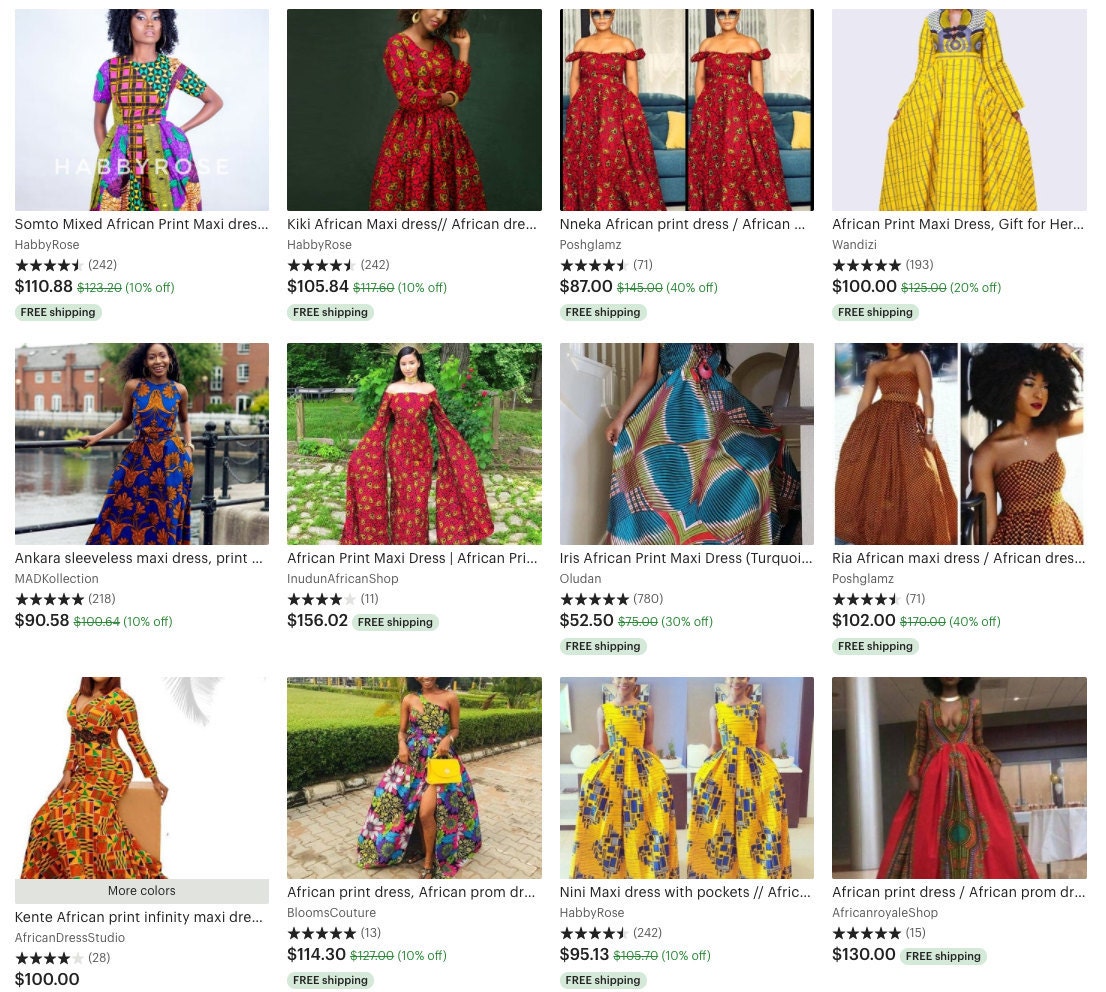
Users also click around less in personalized results, index to fewer pages, and buy more items compared to the control model. This indicates that users are finding what they want faster with the personalized variant.
Overall, personalization features play an important role relative to the existing features for our decision tree. Generally speaking, the importance gain of a feature in a decision tree indicates how much a feature contributes to better predictions. In personalization, contextual features prove to be a strong influence in determining a good final ranking. For users with a richer history of interactions, we provide even better personalized results. This is confirmed by a greater number of purchases online and increased NDCG offline for users that have recently purchased items more than once. Vector representations from recent time windows had greater feature importance gain compared to lifetime vectors. This means that users' recent interactions with listings give a better indication of what the user wants to purchase.
Out of the three user contextual feature types, the text-based Tf-Idf vectors tend to have higher feature importance gain. This might suggest that ranking items based on seller-provided attributes given a query is the best way to help users find what they are looking for.
We also identify users' clicked and favorited items as more important signals compared to past cart adds or purchases. This might indicate that if a user purchased an item once, they have less utility for highly similar items later.
Challenges & Considerations
-
Mentioned in the beginning of the post, serving personalized results online for individual users introduces latency challenges. Typically we rank items in the second pass in real-time and rely on caching to save ordered rankings per query to reduce latency in online serving. But because personalized results are specific to individual users, we have to rank listings for every user and query pair. Cache utilization decreases due to the exploding amount of information we need to store in order to account for each personalized result, which can impact the user experience.
-
Understanding further the appropriate situations to deploy personalized search results can improve a user's experience. For example, when shopping for gifts for your grandmother, would we really want to tailor the results to your taste preferences? There are many ways to achieve this, such as learning the degree of personalization with respect to the query but there might be tradeoffs to latency and training time.
-
For new users who haven't interacted with many listings on our marketplace, we can have an alternative approach for populating default vector values. One possible method would be to set the default vector for new users as the average of all user vectors. However, it's been shown that personalized results are better when a user's individual preferences are very different from the group's average preference.
- Personalization should take into account users’ privacy choices. This can take many forms, such as removing personalization information over time, providing user preferences as to personalization, anonymizing personalization information, or considering the sensitivity of information in how it is used for personalization.
Conclusion
In this post, we have covered how Etsy achieves personalized search ranking results. Our models learn which listings should rank higher for a user based on their own history as well as others' history. These features are encapsulated with user historical features and contextual features. Since launching personalization, users have been able to find items they liked more easily, and they often come back for more. At Etsy, we’re focused on connecting our vibrant marketplace of 3.7 million sellers with shoppers around the world. With the introduction of personalized ranking, we hope to maintain course in our mission to keep commerce human.


