
Modeling User Journeys via Semantic Embeddings

Etsy is a global marketplace for unique goods. This means that as soon as an item becomes popular, it runs the risk of selling out. Machine learning solutions that simply memorize the popular items are not as effective, and crafting features that generalize well across items in our inventory is important. In addition, some content features such as titles are sometimes not as informative for us since these are seller provided, and can be noisy.
In this blog post, I will cover a machine learning technique we are using at Etsy that allows us to extract meaning from our data without the use of content features like titles, modeling only the user journeys across the site. This post assumes understanding of machine learning concepts, specifically word2vec.
What are embeddings?
Word2vec is a popular method in natural language processing for learning a semi-supervised model from unsupervised data to discover similarity across words in a corpus using an unlabelled body of text. This is done by relating co-occurrence of words and relies on the assumption that words that appear together are more related than words that are far apart.
This same method can be used to model user interactions on Etsy by modeling users journeys in aggregate as a sequence of user actions. Each user session is analogous to a sentence, and each user action (clicking on an item, visiting a shop's home page, issuing a search query) is analogous to a word in NLP word2vec parlance. This method of modeling interactions allows us to represent items or other entities (shops, locations, users, queries) as low dimensional continuous vectors (semantic embeddings), where the similarity across two different vectors represents their co-relatedness. This method can be used without knowing anything about any particular user.
Semantic embeddings are agnostic to the content of items such as their titles, tags, descriptions, and allow us to leverage aggregate user interactions on the site to extract items that are semantically similar. In addition, they give us the ability to embed our search queries, items, shops, categories, and locations in the same vector space. This leads to better featurization and candidate selection across multiple machine learning problems, and provides compression, which drastically improves inference speeds compared to representing them as one-hot encodings. Modeling user journeys as a sequence of actions gives us information that is different from content-based methods that leverage descriptions and titles of items, and so these methods can be used in conjunction.
We have already productionized use of these embeddings across product recommendations, guided search experiences and they show great promise on our ranking algorithms as well. External to Etsy, similar semantic embeddings have been used to successfully learn representations for delivering ads as product recommendations via email and matching relevant ads to queries at Yahoo; and to improve their search ranking and derive similar listings for recommendations at AirBnB.
Approach
Etsy has over 50 million active items listed on the site from over 2 million sellers, and tens of millions of unique search queries each month. This amounts to billions of tokens (items or user actions - equivalent to word in NLP word2vec) for training. We were able to train embeddings on a single box, but we quickly ran into some limitations when modeling a sequence of user interactions as a naive word2vec model. The output embedding we constructed did not give us satisfactory performance. This gave us further assurance that some extensions to the standard word2vec implementation were necessary, and so extended the model with additional signals that are discussed below.
Skip-gram model and extensions
We initially started training the embeddings as a Skip-gram model with negative sampling (NEG as outlined in the original word2vec paper) method. The Skip-gram model performs better than the Continuous Bag Of Words (CBOW) model for larger vocabularies. It models the context given a target token and attempts to maximize the average likelihood of seeing any of the context tokens given a target token. The negative sampling draws a negative token from the entire corpus with a frequency that is directly proportional to the frequency of the token appearing in the corpus.
Training a Skip-gram model on only randomly selected negatives, however, ignores implicit contextual signals that we have found to be indicative of user preference in other contexts. For example, if a user clicks on the second item for a search query, the user most likely saw, but did not like, the first item that showed up in the search results. We extend the Skip-gram loss function by appending these implicit negative signals to the Skip-gram loss directly.
Similarly, we consider the purchased item in a particular session to be a global contextual token that applies to the entire sequence of user interactions. The intuition behind this is that there are many touch points on the user’s journey that help them come to the final purchase decision, and so we want to share the purchase intent across all the different actions that they took. This is also referred to as the linear multi-touch attribution model.
In addition, we want to be able to give a user journey that ended in a purchase more importance in the model. We define an importance weight per user interaction (click, dwell, add to cart, and purchase) and incorporate this to our loss function as well.
The details of how we extended Skip-gram are outside the scope of this post but can be found in detail in the Scalable Semantic Matching paper.
Training
We aim to learn a vector representation for each unique token, where a token can be listing id, shop id, query, category, or anything else that is part of a user’s interaction. We were able to train embeddings up to 100 dimensions on a single box. Our final models take in billions of tokens and are able to produce embeddings for tens of millions of unique tokens.
User action can be broadly defined to any sort of explicit or implicit engagement of the user with the product. We extract user interactions from multiple sources such as the search, category, market, and shop home pages, where these interactions are aggregated and not tied to a particular user.
The model performed significantly better when we thresholded tokens based on their type. For example, the frequency count and distribution for queries tend to be very different from that of items, or shops. User queries are unbounded and have a very long tail, and order of magnitudes larger than the number of shops. So we want to capture all the shops in the embeddings vector space whereas limit queries or items based on a cutoff.
We also found a significant improvement in performance by training the model on the past year’s data for the current and upcoming month to add some forecasting capabilities, eg. for a model serving production in the month of December, last month December and January data was added, so our model would see more interactions related to Christmas during this time.
Training application specific models gave us better performance. For example, if we are interested in capturing shop level embeddings, training on the shops for an item instead of just the items directly yields better performance than averaging the embeddings for all items from a particular shop. We are actively experimenting with these models and plan to incorporate user and session specific data in the future.
Results
These are some interesting highlights of what the semantic embeddings are able to capture:
Note that all these relations are created without the model being fed any content features. These are results of the embeddings filtered to just search queries and projected onto tensorboard.
This first set of query similarities captures many different animals for the query jaguar. The second set shows the model also able to relate across different languages. Montre is watch in French, armbanduhr is wristwatch in German, horloge is clock in French, orologio da polso is wristwatch in Italian, uhren is again watch in German, and relog in Spanish.

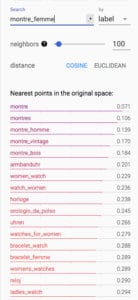
Estate pipe signifies tobacco pipes that are previously owned. Here, we find the the model able to identity different items the pipe is made from (briar, corn cob, meerschaum), different brands of manufacturers (Dunhill and Peterson), and identifies accessories that are relevant to this particular type of pipe (pipe tamper) while not showing correlation with glass pipes that are not valid in this context. Content based methods have not been very effective in dealing with this. The embeddings are able to capture different styles, with boho, gypsy, hippie, gypsysoul all being related styles to bohemian.


We found semantic embeddings to also provide better similar items to a particular item compared to a candidate set generation model that is based on content. This example comes from a model we released recently to generate similar items across shops.
For an item that is a cookie of steer and cacti design, we see the previous method latch onto content from the term ‘steer’ and ignore ‘cactus’, whereas the semantic embeddings place significance on cookies. We find that this has the advantage of not having to guess the importance of a particular item, and just rely on user engagement to guide us.
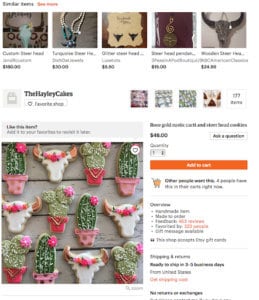

These candidates are generated based on a k-nn search across the semantic representations of items. We were able to run state of the art recall algorithms, unconstrained by memory on our training boxes themselves.
We are excited about the variety of different applications of this model ranging from personalization to ranking to candidate set selection. Stay tuned!
This work is a collaboration between Xiaoting Zhao and Nishan Subedi from the Search Ranking team. We would like to thank our manager, Liangjie Hong for insightful discussions and support, the Recommendation Systems and Search Ranking teams for their input during the project, specially Raphael Louca and Adam Henderson for launching products based on models, Stan Rozenraukh, Allison McKnight and Mohit Nayyar for reviewing this post, and Mihajlo Grbovic, leading author of the semantic embeddings paper for detailed responses to our questions.


