
Deploying to Google Kubernetes Engine

Late last year, Etsy announced that we’ll be migrating our services out of self-managed data centers and into the cloud. We selected Google Cloud Platform (GCP) as our cloud provider and have been working diligently to migrate our services. Safely and securely migrating services to the cloud requires them to live in two places at once (on-premises and in the cloud) for some period of time.
In this article, I’ll describe our strategy specifically for deploying to a pair of Kubernetes clusters: one running in the Google Kubernetes Engine (GKE) and the other on-premises in our data center. We’ll see how Etsy uses Jenkins to do secure Kubernetes deploys using authentication tokens and GCP service accounts. We’ll learn about the challenge of granting fine-grained GKE access to your service accounts and how Etsy solves this problem using Terraform and Helm.
Deploying to On-Premises Kubernetes
Etsy, while new to the Google Cloud Platform, is no stranger to Kubernetes. We have been running our own Kubernetes cluster inside our data center for well over a year now, so we already have a partial solution for deploying to GKE, given that we have a system for deploying to our on-premises Kubernetes.
Our existing deployment system is quite simple from the perspective of the developer currently trying to deploy: simply open up Deployinator and press a series of buttons! Each button is labeled with its associated deploy action, such as “build and test” or “deploy to staging environment.”
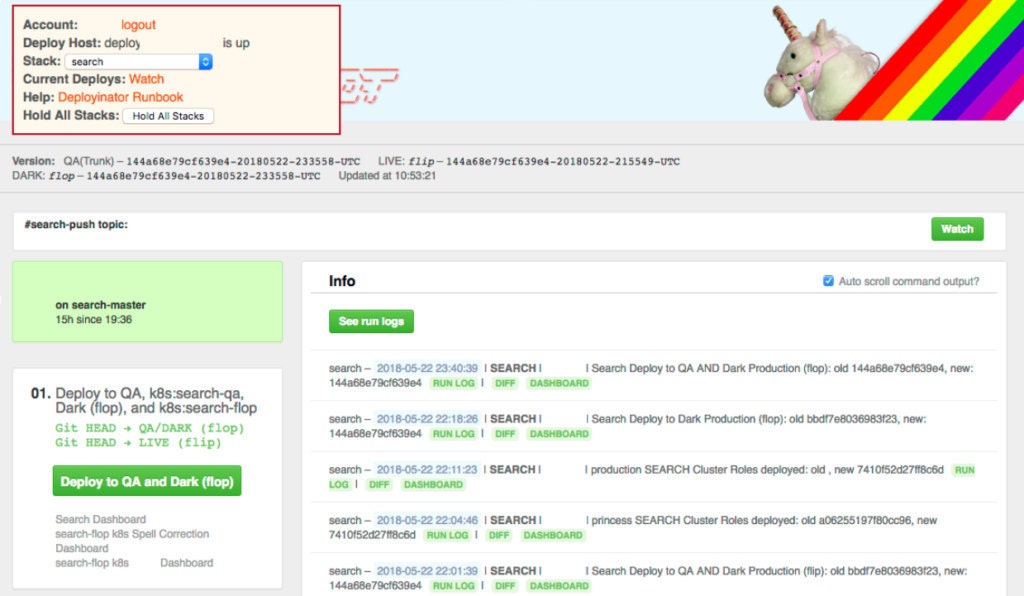
Under the hood, each button is performing some action, such as calling out to a bash script or kicking off a Jenkins integration test, or some combination of several such actions.
For example, the Kubernetes portion of a Search deploy calls out to a Jenkins pipeline, which subsequently calls out to a bash script to perform a series of “docker build”, “docker tag”, “docker push”, and “kubectl apply” steps.
Why Jenkins, then? Couldn’t we perform the docker/kubectl actions directly from Deployinator?
The key is in… the keys! In order to deploy to our on-premises Kubernetes cluster, we need a secret access token. We load the token into Jenkins as a “credential” such that it is stored securely (not visible to Jenkins users), but we can easily access it from inside Jenkins code.
Now, deploying to Kubernetes is a simple matter of looking up our secret token via Jenkins credentials and overriding the “kubectl” command to always use the token.
Our Jenkinsfile for deploying search services looks something like this:
def withKubernetesEnvs(Closure body) {
withCredentials([string(credentialsId: 'secret-k8s-token', variable: 'K8S_TOKEN')]) {
withEnv([
// Ensure that kubectl is using our special robot deployer’s kubeconfig
"KUBECONFIG=/home/[jenkins_user]/.kube/kubernetes_deployment_config",
"KUBECTL=kubectl --token $K8S_TOKEN",
]) {
// Execute the code that is now wrapped with the correct kubectl
body.call()
}
}
}
stage('Deploy k8s services') {
dir('Search') {
withKubernetesEnvs {
kubernetes_deployments = [
spell_correction: {
sh 'apps/spell_correction/kubernetes/deploy.sh';
},
mixer: {
sh 'apps/mixer/kubernetes/deploy.sh';
},
listings_search: {
sh 'apps/listings_search/kubernetes/deploy.sh';
},
]
parallel kubernetes_deployments
}
}
}All of the deploy.sh scripts above use environment variable $KUBECTL in place of standard calls to kubectl, and so by wrapping everything in our withKubernetesEnvs closure, we have ensured that all kubectl actions are using our secret token to authenticate with Kubernetes.
Declarative Infrastructure via Terraform
Deploying to GKE is a little different than deploying to our on-premises Kubernetes cluster and one of the major reasons is our requirement that everything in GCP be provisioned via Terraform. We want to be able to declare each GCP project and all its resources in one place so that it is automatable and reproducible. We want it to be easy—almost trivial—to recreate our entire GCP setup again from scratch. Terraform allows us to do just that.
We use Terraform to declare every possible aspect of our GCP infrastructure. Keyword: possible. While Terraform can create our GKE clusters for us, it cannot (currently) create certain types of resources inside of those clusters. This includes Kubernetes resources which might be considered fundamental parts of the cluster’s infrastructure, such as roles and rolebindings.
Access Control via Service Accounts
Among the objects that are currently Terraformable: GCP service accounts! A service account is a special type of Google account which can be granted permissions like any other user, but is not mapped to an actual user. We typically use these “robot accounts” to grant permissions to a service so that it doesn’t have to run as any particular user (or as root!).
At Etsy, we already have “robot deployer” user accounts for building and deploying services to our data center. Now we need a GCP service account which can act in the same capacity.
Unfortunately, GCP service accounts only (currently) provide us with the ability to grant complete read/write access to all GKE clusters within the same project. We’d like to avoid that! We want to grant our deployer only the permissions that it needs to perform the deploy to a single cluster. For example, a deployer doesn’t need the ability to delete Kubernetes services—only to create or update them.
Kubernetes provides the ability to grant more fine-grained permissions via role-based access control (RBAC). But how do we grant that kind of permission to a GCP service account?
We start by giving the service account very minimal read-only access to the cluster. The service account section of the Terraform configuration for the search cluster looks like this:
# Declare a special IAM role
resource "google_project_iam_custom_role" "minimal-k8s-role" {
role_id = "Minimalk8sIamRole"
title = "Minimal IAM role for GKE access"
description = "Bare minimum permissions to access the kubernetes API."
project = "${google_project.project.project_id}"
permissions = [
"container.apiServices.get",
"container.apiServices.list",
"container.clusters.get",
"container.clusters.getCredentials",
]
}
# Create our service account
resource "google_service_account" "search-deployer" {
account_id = "search-deployer"
display_name = "search-deployer"
}
# Assign the special IAM role to the service account
resource "google_project_iam_member" "search-deployer-gke-access" {
project = "${google_project.project.project_id}"
role = "projects/${google_project.project.project_id}/roles/Minimalk8sIamRole"
member = "serviceAccount:${google_service_account.search-deployer.email}"
}
# Store the service account key in Terraform so that we can access it
resource "google_service_account_key" "search-deployer" {
service_account_id = "${google_service_account.search-deployer.id}"
}We have now created a service account with read-only access to the GKE cluster. Now how do we associate it with the more advanced RBAC inside GKE? We need some way to grant additional permissions to our deployer by using a RoleBinding to associate the service account with a specific Role or ClusterRole.
Solving RBAC with Helm
While Terraform can’t (yet) create the RBAC Kubernetes objects inside our GKE cluster, it can be configured to call a script (either locally or remotely) after a resource is created.
Problem solved! We can have Terraform create our GKE cluster and the minimal deployer service account, then simply call a bash script which creates all the Namespaces, ClusterRoles, and RoleBindings we need inside that cluster. We can bind a role using the service account’s email address, thus mapping the service account to the desired GKE RBAC role.
However, as Etsy has multiple GKE clusters which all require very similar sets of objects to be created, I think we can do better. In particular, each cluster will require service accounts with various types of roles, such as “cluster admin” or “deployer”. If we want to add or remove a permission from the deployer accounts across all clusters, we’d prefer to do so by making the change in one place, rather than modifying multiple scripts for each cluster.
Good news: there is already a powerful open source tool for templating Kubernetes objects! Helm is a project designed to manage configured packages of Kubernetes resources called “charts”.
We created a Helm chart and wrote templates for all of the common resources that we need inside GKE. For each GKE cluster, we have a yaml file which declares the specific configuration for that cluster using the Helm chart’s templates.
For example, here is the yaml configuration file for our production search cluster:
ClusterAdmins:
- [redacted] # emails of search team members
Namespaces:
- NamespaceName: "search-flip"
RobotDeployer: "search-deployer@[project].iam.gserviceaccount.com"
Quotas:
requests.cpu: "180"
requests.memory: 200Gi
- NamespaceName: "search-flop"
RobotDeployer: "search-deployer@[project].iam.gserviceaccount.com"
Quotas:
requests.cpu: "180"
requests.memory: 200GiAnd here are the templates for some of the resources used by the search cluster, as declared in the yaml file above (or by nested references inside other templates)...
#
# A ClusterRoleBinding that grants UNFETTERED ACCESS TO THE CLUSTER to the
# Users and Groups listed in the 'ClusterAdmins' and 'ClusterAdminGroups' keys
#
# This should be reserved for administrators of the cluster, regular usage doesn't require such power, role binding namespace-owner is more suitable in most cases.
#
{{ if or .Values.ClusterAdmins .Values.ClusterAdminGroups }}
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: etsy-cluster-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
{{ range $index, $userEmail:= .Values.ClusterAdmins }}
- apiGroup: rbac.authorization.k8s.io
kind: User
name: {{ $userEmail }}
{{ end }}
{{ range $index, $groupName:= .Values.ClusterAdminGroups }}
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: {{ $groupName }}
{{ end }}
{{ end }}And also...
#
# A set of objects for configuring namespaces, their quotas (limited to 1 quota),
# a deployer user that is given the robot-deployer ClusterRole,
# and a list of users/groups in the namespace that are given the namespace-owner ClusterRole
#
{{- if .Values.Namespaces }}
{{- range $index, $namespace:= .Values.Namespaces}}
apiVersion: v1
kind: Namespace
metadata:
name: {{ $namespace.NamespaceName }}
---
{{- if $namespace.Quotas }}
apiVersion: v1
kind: ResourceQuota
metadata:
name: {{ $namespace.NamespaceName }}-resourcequota
namespace: {{ $namespace.NamespaceName }}
spec:
hard:
resourcequotas: "1"
{{- if $namespace.Quotas}}
{{- range $name, $value := $namespace.Quotas }}
{{ $name }}: {{ $value }}
{{- end }}
{{- end }}
{{- end }}
---
{{- if $namespace.RobotDeployer }}
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: {{ $namespace.NamespaceName }}-robot-deployer
namespace: {{ $namespace.NamespaceName }}
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: robot-deployer
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: {{ $namespace.RobotDeployer }}
{{- end }}
---
{{- if or $namespace.NamespaceOwners $namespace.NamespaceOwnerGroups }}
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: {{ $namespace.NamespaceName }}-owner
namespace: {{ $namespace.NamespaceName }}
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: namespace-owner
subjects:
{{- range $index, $userEmail:= $namespace.NamespaceOwners}}
- apiGroup: rbac.authorization.k8s.io
kind: User
name: {{ $userEmail }}
{{- end }}
{{- range $index, $groupName:= $namespace.NamespaceOwnerGroups}}
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: {{ $groupName }}
{{- end }}
{{- end }}
---
{{- end }}
{{- end }}#
# A role for granting the permissions deemed necessary for deploying to kubernetes
#
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: robot-deployer
rules:
- apiGroups:
- ""
resources:
- containers
- endpoints
- services
- pods
verbs:
- create
- get
- list
- patch
- update
- watch
# and so on for other sets of apiGroups, resources, and verbsWhen we are ready to apply a change to the Helm chart—or Terraform is applying the chart to an updated GKE cluster—the script which applies the configuration to the GKE cluster does a simple “helm upgrade” to apply the new template values (and only the new values! Helm won’t do anything where it detects that no changes are needed).
Integrating our New System into the Pipeline
Now that we have created a service account which has exactly the permissions we require to deploy to GKE, we only have to make a few simple changes to our Jenkinsfile in order to put our new system to use.
Recall that we had previously wrapped all our on-premises Kubernetes deployment scripts in a closure which ensured that all kubectl commands use our on-premises cluster token. For GKE, we use the same closure-wrapping style, but instead of overriding kubectl to use a token, we give it a special kube config which has been authenticated with the GKE cluster using our new deployer service account. As with our secret on-premises cluster token, we can store our GCP service account key in Jenkins as a credential and then access it using Jenkins’ withCredentials function.
Here is our modified Jenkinsfile for deploying search services:
def withOnPremKubernetesEnvs(Closure body) {
withCredentials([string(credentialsId: 'secret-k8s-token', variable: 'K8S_TOKEN')]) {
withEnv([
// Ensure that kubectl is using our special robot deployer’s kubeconfig
"KUBECONFIG=/home/[jenkins_user]/.kube/kubernetes_deployment_config",
"KUBECTL=kubectl --token $K8S_TOKEN",
]) {
// Execute the code that is now wrapped with the correct kubectl
body.call()
}
}
}
def withGKEEnvs(Closure body) {
withCredentials([string(credentialsId: 'search-deployer-key', variable: 'SERVICE_ACCOUNT_KEY_FILE')]) {
try {
// Authenticate as the robot deployer service account
sh 'gcloud auth activate-service-account search-deployer@[project].iam.gserviceaccount.com --key-file=$SERVICE_ACCOUNT_KEY_FILE'
// Avoid clobbering an existing kubeconfig
sh 'export KUBECONFIG=$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )/kubeconfig'
// Setup kubectl for gke
sh 'gcloud container clusters get-credentials "[cluster]" --zone "[zone]" --project "[project]"'
withEnv([
"KUBECTL=kubectl",
]) {
// Execute the code that is now wrapped with the correct kubectl and config
body.call()
}
} finally {
sh 'gcloud auth revoke'
}
}
}
stage('Deploy k8s services') {
dir('Search') {
on_prem_kubernetes_deployments = [
mixer: {
sh 'apps/mixer/kubernetes/deploy.sh';
},
listings_search: {
sh 'apps/listings_search/kubernetes/deploy.sh';
},
]
// In this example, we moved the spelling correction service to GKE
gke_deployments = [
spell_correction: {
sh 'apps/spell_correction/kubernetes/deploy.sh';
},
]
withOnPremKubernetesEnvs {
parallel on_prem_kubernetes_deployments
}
withGKEEnvs {
parallel gke_deployments
}
}
}And there you have it, folks! A Jenkins deployment pipeline which can simultaneously deploy services to our on-premises Kubernetes cluster and to our new GKE cluster by associating a GCP service account with GKE RBAC roles.
Migrating a service from on-premises Kubernetes to GKE is now (in simple cases) as easy as shuffling a few lines in the Jenkinsfile. Typically we would deploy the service to both clusters for a period of time and send a percentage of traffic to the new GKE version of the service under an A/B test. After concluding that the new service is good and stable, we can stop deploying it on-premises, although it’s trivial to switch back in an emergency.
Best of all: absolutely nothing has changed from the perspective of the average developer looking to deploy their code. The new logic for deploying to GKE remains hidden behind the Deployinator UI and they press the same series of buttons as always.
--
Thanks to Ben Burry, Jim Gedarovich, and Mike Adler who formulated and developed the Helm-RBAC solution with me.


