
How Etsy caches: hashing, Ketama, and cache smearing

At Etsy, we rely heavily on memcached and Varnish as caching tiers to improve performance and reduce load. Database and search index query results, expensive calculations, and more are stored in memcached as a look-aside cache read from PHP and Java. Internal HTTP requests between API servers are sent through and cached in Varnish. As traffic has grown, so have our caching pools. Today, our caching clusters store terabytes of cached data and handle millions of lookups per second.
At this scale, a single cache host can't handle the volume of reads and writes that we require. Cache lookups come from thousands of hosts, and the total volume of lookups would saturate the network and CPU of even the beefiest hardware---not to mention the expense of a server with terabytes of RAM. Instead, we scale our caches horizontally, by building a pool of servers, each running memcached or Varnish.
In memcached, the cache key can be (almost) any string, which will be looked up in the memcached server's memory. As an HTTP cache, Varnish is a bit more complex: requests for cacheable resources are sent directly to Varnish, which constructs a cache key from the HTTP request. It uses the URL, query parameters, and certain headers as the key. The headers to use in the key are specified with the Vary header; for instance, we include the user's locale header in the cache key to make sure cached results have the correct language and currency. If Varnish can't find the matching value in its memory, it forwards the request to a downstream server, then caches and returns the response.
With large demands for both memcached and varnish, we want to make efficient use of the cache pool's space. A simple way to distribute your data across the cache pool is to hash the key to a number, then take it modulo the size of the cache pool to index to a specific server. This makes efficient use of your cache space, because each cached value is stored on a single host---the same host is always calculated for each key.
Consistent hashing for scalability
A major drawback of modulo hashing is that the size of the cache pool needs to be stable over time. Changing the size of the cache pool will cause most cache keys to hash to a new server. Even though the values are still in the cache, if the key is distributed to a different server, the lookup will be a miss. That makes changing the size of the cache pool---to make it larger or for maintenance---an expensive and inefficient operation, as performance will suffer under tons of spurious cache misses.
For instance, if you have a pool of 4 hosts, a key that hashes to 500 will be stored on pool member 500 % 4 == 0 , while a key that hashes to 1299 will be stored on pool member 1299 % 4 == 3 . If you grow your cache by adding a fifth host, the cache pool calculated for each key may change. The key that hashed to 500 will still be found on pool member 500 % 5 == 0 , but the key that hashed to 1299 be on pool member 1299 % 5 == 4 . Until the new pool member is warmed up, your cache hit rate will suffer, as the cache data will suddenly be on the ‘wrong’ host. In some cases, pool changes can cause more than half of your cached data to be assigned to a different host, slashing the efficiency of the cache temporarily. In the case of going from 4 to 5 hosts, only 20% of cache keys will be on the same host as before!
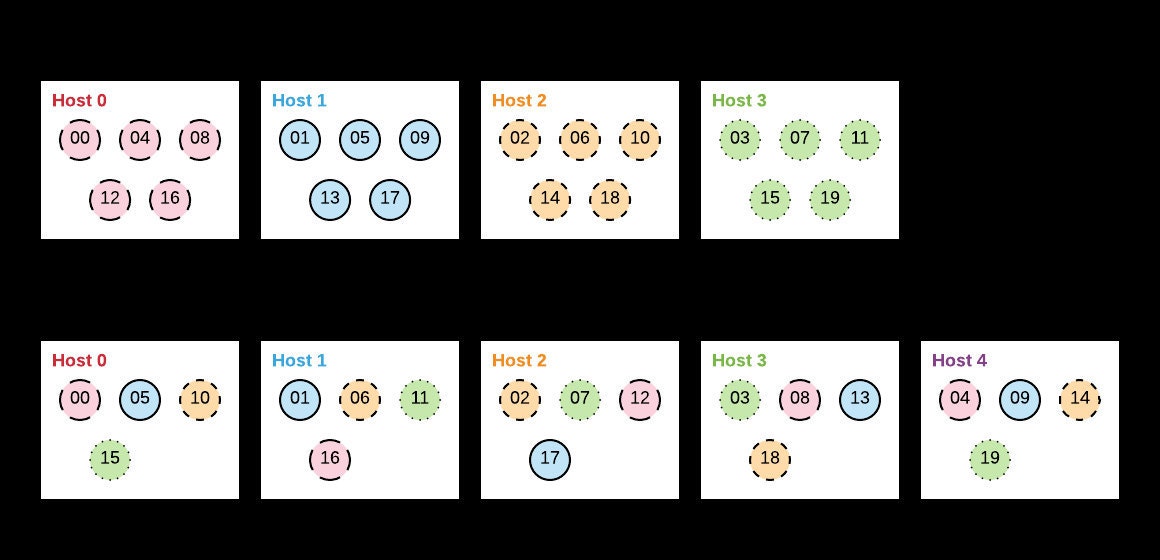
A fixed-size pool, with changes causing the hit rate to suffer, isn't acceptable. At Etsy, we make our memcached pools more flexible with consistent hashing, implemented with Ketama. Instead of using the modulo operation to map the hash output to the cache pool, Ketama divides the entire hash space into large contiguous buckets, one (or more) per cache pool host. Cache keys that hash to each range are looked up on the matching host. This consistent hashing maps keys to hosts in such a way that changing the pool size only moves a small number of keys---"consistently" over time and pool changes.
As a simplified example, with 4 hosts and hash values between 0 and 2^32-1, Ketama might map all values in [0, 2^30) to pool member 0, [2^30, 2^31) to pool member 1, and so on. Like modulo, this distributes cache keys evenly and consistently among the cache hosts. But when the pool size changes, Ketama results in fewer keys moving to a different host.
In the case of going from four hosts to five, Ketama would now divide the hash outputs into 5 groups. 50% of the cache keys will now be on the same host as previously. This leads to fewer cache misses and more efficiency during pool changes.
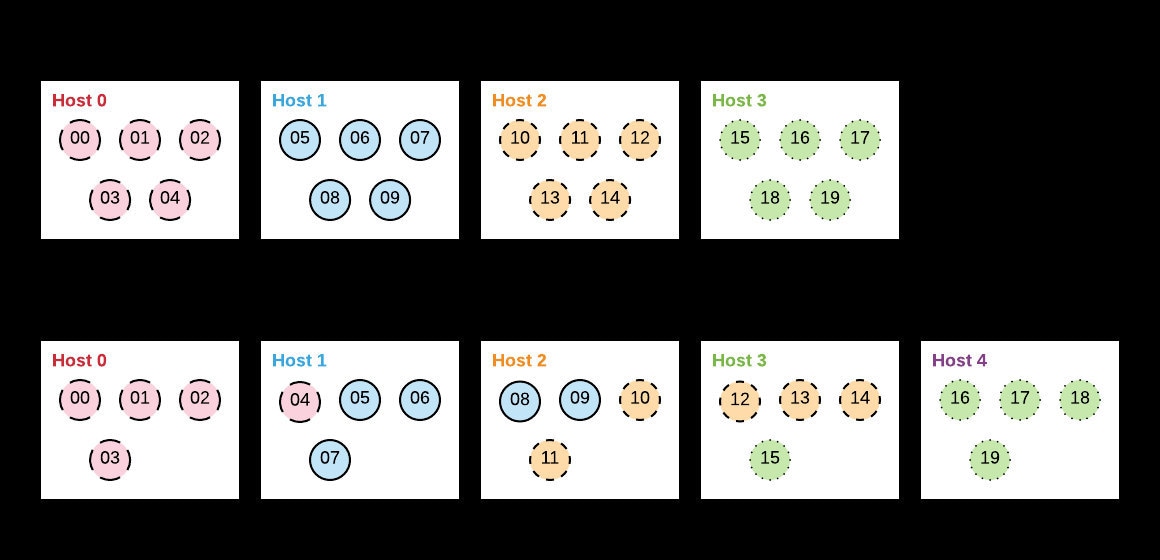
In reality, Ketama maps each host to dozens or hundreds of buckets, not just one, which increases the stability and evenness of hashing. Ketama hashing is the default in PHP's memcached library, and has served Etsy well for years as our cache has grown. The increased efficiency of consistently finding keys across pool changes avoids expensive load spikes.
Hot keys and cache smearing
While consistent hashing is efficient there is a drawback to having each key exist on only one server. Different keys are used for different purposes, and certain cache items will be read and written more than others. In our experience, cache key read rates follow a power law distribution: a handful of keys are used for a majority of reads, while the majority of keys are read a small number of times. With a large number of keys and a large pool, a good hash function will distribute the "hot keys"---the most active keys---among many servers, smoothing out the load.
However, it is possible for a key to be so hot---read so many times---that it overloads its cache server. At Etsy, we've seen keys that are hit often enough, and store a large enough value, that they saturate the network interface of their cache host. The large number of clients are collectively generating a higher read rate than the cache server can provide. We've seen this problem many times over the years, using mctop, memkeys, and our distributed tracing tools to track down hot keys.
Further horizontal scaling by adding more cache hosts doesn't help in this case, because it only changes the distribution of keys to hosts---at best, it would only move the problem key and saturate a different host. Faster network cards in the cache pool also help, but can have a substantial hardware cost. In general, we try to use large numbers of lower-cost hardware, instead of relying a small number of super-powered hosts.
We use a technique I call cache smearing to help with hot keys. We continue to use consistent hashing, but add a small amount of entropy to certain hot cache keys for all reads and writes. This effectively turns one key into several, each storing the same data and letting the hash function distribute the read and write volume for the new keys among several hosts.
Let’s take an example of a hot key popular_user_data . This key is read often (since the user is popular) and is hashed to pool member 3. Cache smearing appends a random number in a small range (say, [0, 8) ) to the key before each read or write. For instance, successive reads might look up popular_user_data3 , popular_user_data1 , and popular_user_data6 . Because the keys are different, they will be hashed to different hosts. One or more may still be on pool member 3, but not all of them will be, sharing the load among the pool.
Cache smearing (named after the technique of smearing leap seconds over time) trades efficiency for throughput, making a classic space-vs-time tradeoff. The same value is stored on multiple hosts, instead of once per pool, which is not maximally efficient. But it allows multiple hosts to serve requests for that key, preventing any one host from being overloaded and increasing the overall read rate of the cache pool.
We manually add cache smearing to only our hottest keys, leaving keys that are less read-heavy efficiently stored on a single host. We 'smear' keys with just a few bits of entropy, that is, with a random number in a small range like 0 to 8 or 0 to 16. Choosing the size of that range is its own tradeoff. A too-large range duplicates the cached data more than necessary to reduce load, and can lead to data inconsistencies if a single user sees smeared values that are out-of-sync between multiple requests. A too-small range doesn't spread the load effectively among the cache pool (and could even result in all the smeared keys still being hashed to the same pool member).
We've successfully smeared both memcached keys (by appending entropy directly to the key) and Varnish keys (with a new query parameter for the random value). While we could improve the manual process to track down and smear hot keys, the work we've done so far has been integral to scaling our cache pools to their current sizes and beyond.
The combination of consistent hashing and cache smearing has been a great combination of efficiency and practicality, using our cache space well while ameliorating the problems caused by hot keys. Keep these approaches in mind as you scale your caches!
You can follow me on Twitter at @kevingessner


