
API First Transformation at Etsy - Concurrency

At Etsy we have been doing some pioneering work with our Web APIs. We switched to API-first design, have experimented with concurrency handling in our composition layer, introduced strong typing into our API design, experimented with code generation, and built distributed tracing tools for API as part of this project.
We faced a common challenge: much of our logic was implemented twice. All of the code that was built for the website then had to be rebuilt in our API to be used by our iOS and Android apps.
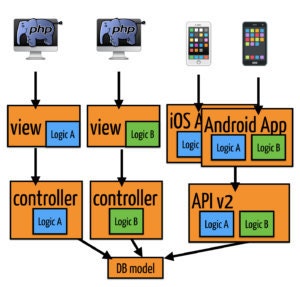
Problem: repeated logic between platforms
We wanted an approach where we built everything on reusable API components that could be shared between the web and apps. Unfortunately our existing API framework couldn't support this shared approach. The solution we settled on was to abandon the existing framework and rebuild it from scratch.
Follow along this case study of building an API First architecture, in which functional changes are expressed on the API level before integrating them into the website. Hear what problems prompted this drastic change. Learn which new tools we had to build to be able to work with the new system and what mistakes we made along the way. Finally, how did it end? How did the team adopt the new system and have we succeeded in our goals of API First?
This post will be the first post in a series about our current API infrastructure, which we call version 3. The series is based on a talk at QCon New York. The first post will cover concurrency, the second post will cover operations and the third post the human aspects of our API transition.
First problem: More devices & platforms (also: JavaScript)
If we look into the future, it comes with lots of devices. Mainframes became desktop computers, which became portable laptops and tablets, smart phones and watches.
This trend has been going on for a while, and in order to not reinvent the world on each different device, we started sharing data via an internal API years ago.
The first version of Etsy&39;s API was a gateway for flash widgets. And the second one was a JSON RESTful API for 3rd parties and internal use. It was tightly coupled to the underlying database schema, and it empowered clients to make customized complex requests. It was so powerful that when we introduced our first iPad App, we did not need to write any new endpoints, and could build it solely on existing ones. Clients could request multiple resources at once, for example request shop data and also include listing data from that shop, and they could specify fields to trim down the response to just the required data. Very powerful.
Second Problem: Performance & complexity control
With great power comes great responsibility, and this approach had some drawbacks. The server code was simple, but we did not know the incoming parameters. We gave the clients control over the complexity of the request via the request parameters. This obviously had implications on server-side performance. And measuring the performance was difficult, because it was not clear if an increased response time was due to the performance of our backend, or because the client requested more resources.
Third Problem: Repetition & inconsistency
Years of changing patterns and an evolving complex codebase with MVC architecture led to bad habits: data fetch during template rendering, and logic in the templates. Our API was for AJAX, whereas the backend code was in PHP. We did not have the logic in one place that was reusable for both the Web and API. This lead to inconsistencies between API and pre-API web.
The schema of the API resource was a snapshot of the data model at the time of exposing it via the endpoint. This one-to-one mapping caused problems with data migrations, as the API resource was "frozen in time". Should it change with the model? How long should the old resource structure be supported?
Requirements for API-first
We re-discussed the requirements for our API. If performance, manifesting for the user as latency from request to response, was a problem, what was the bottleneck?
First, the time to glass, the time until we see something on our device’s screen, as Ilya Grigorik calls it in his talk "breaking the 1000 milliseconds time to glass”, and he states that due to mobile network speed, we have only 100 milliseconds on the server side if we want to stay in budget. The second problem is that we, at Etsy, come from a sequential-shared-nothing-php-world. No built-in concurrency. How can we parallelize and reuse our work, while still keeping the network footprint low?
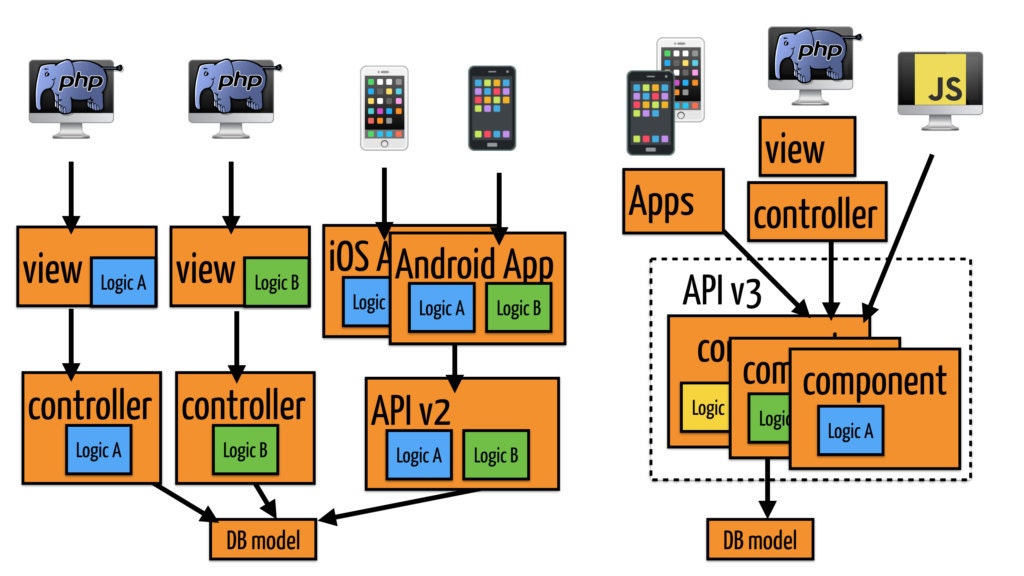
API v2: repeated logic between platforms API v3: reusable components
Other requirements were how to think about caching. The previous version of the API was memcached only, caching calls including parameters, which lead to a granularity problem. And one last requirement was to solve the problem starting from what we know and what we're good at - building our own solutions in PHP.
Shaping our mental model
Based on these learnings, we piece-by-piece architected a new version, called API Version 3. REST resources worked well for both mobile apps and traditional web, so that was a keeper. A new idea was to decouple the endpoints from the framework that hosts them. Minimize the endpoints’ responsibilities to:
- declaring the route
- declaring the input expectations and the output guarantees
- implementing what happens in the endpoint.
.. and that's about it.
We have one very simple, declarative file for each endpoint.
Everything else is architected away on purpose: StatsD error monitoring, endpoint input and output type checks, and the compilation of the full routes -- all of this is handled by the framework. Authentication and access control is also handled there, based on the class of endpoint that the developer has chosen.
Enter the meta-endpoint
We picked up the industry ideas from Netflix and eBay&39;s ql.io of server side composition of resources into device-view-specific resources. Or in other words: allowing a second layer of endpoints that are consumers of our own API, requesting and aggregating other endpoints. This means the server itself is also a client of the API, making the server more complex, while giving it more control with an extra layer for code execution. This improves performance of the client, because it only needs to make one single request - the biggest bottleneck if we want to have a responsive mobile interface!
These requests used our generated PHP client, and they used cURL. cURL? Let&39;s talk about this for a bit. And let&39;s take a step back. The interesting question is how to bring concurrency into the single-threaded world of PHP.
cURL is cool
We're in an HTTP context, so what about making additional HTTP requests for concurrency? We examined whether this could be done with cURL.
Some time in 2013, Paul tweeted
In a hack week project, Paul and Matt from Etsy’s core team figured out that we could in fact achieve concurrency in the HTTP layer, through parallel cURL calls with curl_multi_info read. The HTTP layer is an interesting layer for this, since there are many existing solutions for routing, load balancing and caching.
In addition to cURL, we added logic to establish dependencies on requests to other endpoints, which we call proxies. We are running the requests when the corresponding proxy becomes unblocked, similar to an event loop, which you might know from NodeJS. The whole concurrency dependency analysis and scheduling is encapsulated within one piece of software, which we call the curl callback orchestrator.
This is great, because from the endpoint author&39;s point of view the code looks sequential and single-threaded and is just a list of proxy calls to other endpoints. We’re getting closer to a declarative style, expressing our intent, and the orchestrator figures out how to schedule the calls that are necessary for the complete result.
You Would not Reimplement an API...
Ok, so we had some good observations about the previous versions of our API, and we have a working prototype for concurrency via cURL.
How did we grow an entire new API framework from here?
Perspectives and Services
Two concepts are special about Etsy’s API v3: perspectives and services.
Perspectives clarify data access rules and give us security hints on what code is permitted for each perspective. They express on whose behalf an API call is being made. So, for example, the Public perspective shows data that a logged-out user would be able to see on Etsy.com.

The Member perspective is for calls made on behalf of a particular Etsy member. The user ID is determined via the user cookie or OAuth token, dependent on the Service, which we will talk about below. The Shop perspective is similar to the member perspective but is for a shop. The framework will verify that the given shop is owned by the authenticated user. The Admin perspective is like the member perspective but for Etsy Admin. We occasionally want to take actions from our own servers that may not fit the other perspectives. For this we have the Infrastructure perspective. It is only available on the private internal API and can be used for things such as dataset loading. The application perspective is for calls made on behalf of a particular API application. It contains the application data for the verified API key.
While perspectives express on whose behalf a call is being made, the service indicates from where the call is being made. A service can also be thought of as the entry point into the API framework. Each service has its own requirements regarding authentication. Endpoints are included in some services by default. Other services are opt-in, and each endpoint has to declare whether it wants to be exposed on those opt-in services.

The Ajax service is accessible from pages that run JavaScript on etsy.com. The Admin service is accessible from pages that run JavaScript on our internal admin tools platform. The internal service is used by other API services that are already inside of our API cluster network. The Apps service is accessible from our native apps in iOS and Android. The 3rd party service is for 3rd party app developers. The services separate different application domains.
An example API call
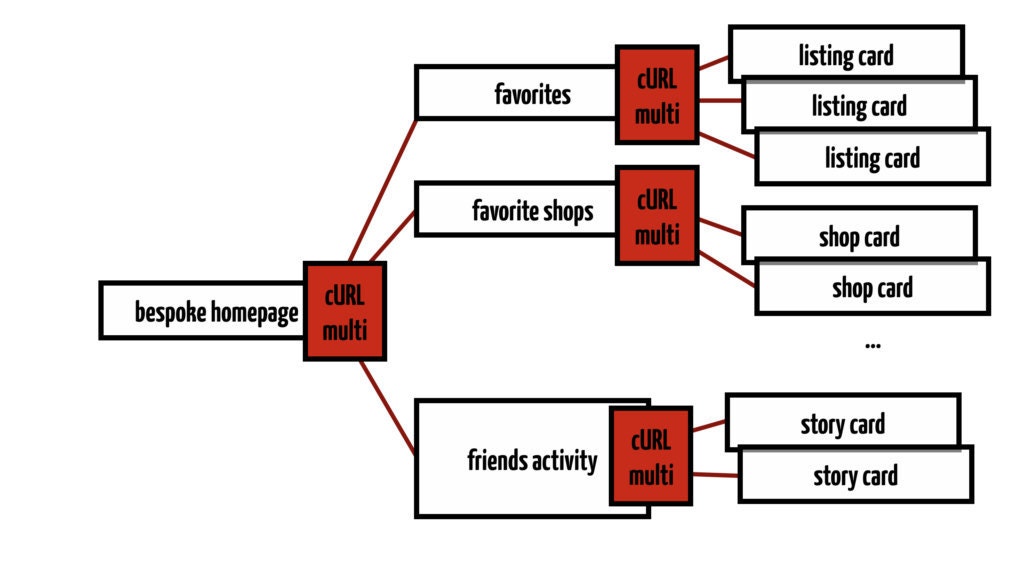
Let’s look at an example request to the etsy.com homepage. We know what the homepage looks like: sections of information that might be interesting for me, as a potential buyer. Up at the top are the listings that I favorited, then some picks that Etsy’s recommendation algorithms picked for me, new items from my favorite shops, activity from my friends, and so on. I think about it as something like this.
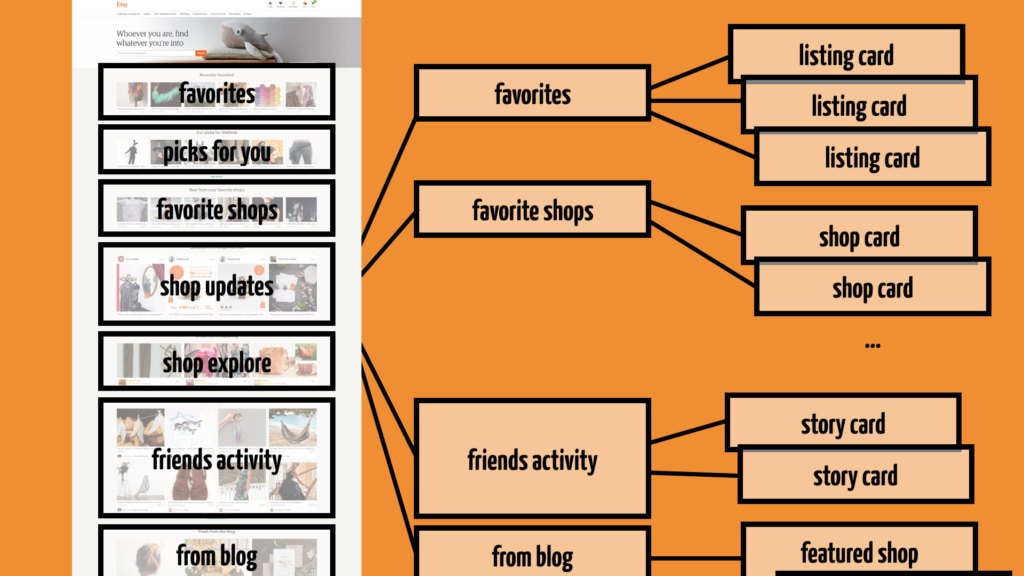
If we look at the data in more detail, we see even more structure. It’s like a tree, growing from left to right.
Our setup of network and servers is mirroring the structure of the API call. It starts with an HTTP request from my browser to Etsy's web server. From there, a bespoke API request is being made to our API server, requesting a personalized version of the homepage data. Internally, this request consists of multiple concurrent components. They themselves are fetched via API requests. Such as my favorites, which are a concurrent component, because they are a large number of listing cards that can be fetched in parallel.
So we can imagine an API request as a multi-level tree, kicking off other API requests and constructing an overall result from the results of those subrequests.
Domain specific language of API endpoints
The project that got me started diving deep into Etsy’s API v3 framework was striving to unify the syntax of API endpoints. This was really fun and involved big, automated changes to unify the API codebase. In the past, there were multiple styles in which endpoints could be written. To unify them, we carved out a language of endpoint building blocks.
Some building blocks are mandatory for each endpoint. Each endpoint needs to declare its route, so we know where it should be found on the web. Also, it needs a human readable description, and a resultType.

The result type describes what type of data the endpoint returns. All data we return is JSON encoded, but here we can say that we return a primitive data type, such as a string or a boolean inside that encoding. Or we could return what we call “a typed resource” - a compound type that refers to a specific component of the Etsy application domain, such as a ListingCard.
And then there is the handle function. In there, every endpoint runs the code that it needs to run, to build its response.

Optional building blocks of an API endpoint are also possible. declareInput is only necessary if the endpoint does actually need input parameters. If it doesn’t, the function can be left out.
The includedServices function allows an endpoint to opt into specific services. The EtsyApps service is opt-in for example, so if you want to make your endpoint available on the apps, you have to opt into the EtsyApps service via this function.
And then there is the cacheTtlSeconds function, which allows you to specify whether an endpoint should be cached, and what should be it’s time to live.
Input and output: Typed parameters, typed result
The first step when a request is being routed to the endpoint, is the setup of the input parameters. We create an input object based on the request’s URL and the endpoint’s declareInput function.
The input declaration tells us how to check for optional or mandatory input parameters, which are parsed according to a pattern in the route. If a parameter is missing or of the wrong type, the framework returns an HTTP error code and message. The input declaration specifies a type for each parameter, such as a string or a user ID. The types are Etsy-specific, and each one comes with its own validation function which is being run by the framework. According to the perspective, information about the logged in user, the logged in admin, shop, or authenticated app is being checked as well, and added to the input object.
Each endpoint specifies its own output type via the resultType function. Currently, those types are optional and of different level of detail. We encourage developers to either return a primitive datatype, or to build a compound type, called typed resource, corresponding to the shape of the data that their endpoint returns. Type guarantees are useful for the API clients, and bring us one step closer to having guarantees on our data from the browser input field to the the database record.
To make our framework complete, we’re still missing some action on both ends. How does an API request get routed to an endpoint? And how can we make an API request from our code, for example inside a meta-endpoint or in JavaScript when our site uses AJAX?
Tooling: API compiler
We need two more pieces of software, which we can automatically compile based on the endpoint declaration files. This is the job of the API compiler. Initially, this was a script that took the routes from the endpoint declarations, together with the service and perspective information, and compiled these into full routes for apache by modifying the .htaccess files. Performance concerns were alleviated by splitting up the work and files by perspective.
Over time, we also added a second part: the generation of API client code in PHP and in JavaScript. The code is being generated using a mustache template, which is a template language for websites, but works well in this context, too. Before we deploy code to Etsy.com, we check if the compiled routes and client code are up to date via Jenkins. In this way, we control both ends of the API stack from the database access code to the outer shape of the endpoint landscape, which is reflected in changes to the client. And we neatly tie this into our continuous deployment process.
This is the first post in a series of three about Etsy’s API, the abstract interface to our logic and data. The next post covers the operational side of Etsy's API.


