
Building a Translation Memory to Improve Machine Translation Coverage and Quality

Machine Translation at Etsy
At Etsy, it is important our global member base can communicate with one another, even when they don’t speak the same language. Whether users are browsing listings, messaging other users, or posting comments in the forums, machine translation is a valuable tool for facilitating multilingual interactions on our site and in our apps.
Listing descriptions account for the bulk of text we machine translate. With over 35 million active listings at an average length of nearly 1,000 characters, and 10 supported site languages, we need to translate a lot of content—and that’s just for listings. We also provide machine translation for listing reviews, forum posts, and conversations (messaging between members). We send text we need to translate to a third party machine translation service, and given the associated cost, there is a limit to the number of characters we can translate per month.
While a user can request a listing translation if we don’t already have one (we call this on-demand translation), translating a listing beforehand and showing a visitor the translation automatically (we call this pre-translation) provides a more fluid browsing experience. Pre-translation also allows listings to surface in search results in multiple languages, both for searches on Etsy and on external search engines like Google.
The Benefits of a Translation Memory
Many of the strings we machine translate from one language to another are text segments we’ve seen before. Our most common segments are used in millions of listings, with a relatively small subset of distinct segments accounting for a very large proportion of the content. For example, the sentence "Thanks for looking!" appears in around 500,000 active listings on Etsy, and has appeared in over 3 million now inactive listings.
 Frequency and rank of text segments (titles, tags, and description paragraphs) appearing in listings on Etsy. The distribution of segments roughly conforms to a classic Zipfian shape, where a string&39;s rank is inversely proportional to its frequency.
Frequency and rank of text segments (titles, tags, and description paragraphs) appearing in listings on Etsy. The distribution of segments roughly conforms to a classic Zipfian shape, where a string&39;s rank is inversely proportional to its frequency.
In the past, a single text segment that appeared in thousands of listings on Etsy would be re-translated once for every listing. It would also be re-translated any time a seller edited a listing. This was a problem: our translation budget was being spent on millions of repeat translations that would be better used to translate unique content into more languages.
To solve this problem, we built a translation memory. At its simplest, a translation memory stores a text segment in one language and a corresponding translation of that segment in another language. Storing strings in a translation memory allows us to serve translations for these strings from our own databases, rather than making repeated requests to the translation service.
Storing these translations for later reuse has two main benefits:
-
Coverage: By storing common translations in the translation memory and serving them ourselves, we drastically reduce the number of duplicate segments we send to the translation service. This process lets us translate seven times more content for the same cost.
- Quality: We’re able to see which text segments are most commonly used on Etsy and have these segments human translated. Overriding these common segments with human translations improves the overall quality of our translations.
Initial Considerations
We had two main concerns when planning the translation memory architecture:
-
Capacity: The more text segments we store in the translation memory, the greater our coverage. However, storing every paragraph from each of our more than 35 million active listings, and a translation of that paragraph for each of our 10 supported languages, would mean a huge database table. Historically, Etsy has rarely had tables exceeding a few billion rows, and we wanted to keep that maximum limit here.
- Deletions: The translation service’s quality is continually improving, and to take full advantage of these improvements we need to periodically refresh entries in the translation memory by deleting older translations. We wanted to be able to delete several hundred million rows on a monthly basis without straining system resources.
The Translation Memory Architecture
Our Translation Memory consists of several separate services, each handling different tasks. A full diagram of the pipeline is below:

A brief overview of each step:
-
Splitting into segments: The first step of the translation pipeline is splitting blocks of text into individual segments. The two main choices here were splitting by sentence or splitting by paragraph. We chose the latter for a few reasons. Splitting by sentence gave us more granularity, but our estimated Translation Memory hit rate was only 5% higher with sentences versus paragraphs. The increased hit rate wasn’t high enough to warrant the extra logic needed to split by sentence, nor the multi-fold database size increase to store every sentence, instead of just every paragraph. Moreover, although automatic sentence boundary detection systems can be quite good, a recent study evaluated the most popular systems on user-generated content and found that accuracy peaked at around 95%. In contrast, using newline characters to split paragraphs is straightforward and an almost error-free way to segment text.
-
Excluder: The excluder is the first service we run translations through. It removes any text we don’t want to translate. For now this means lines containing only links, numbers, or special characters.
- Human Translation Memory (HTM): Before looking for a machine translation, we check first for an existing human translation. Human translations are provided by Etsy’s professional translators (the same people who translate Etsy’s static site content). These strings are stored in a separate table from the Machine Translation Memory and are updated using an internal tool we built, pictured below.

-
Machine Translation Memory (MTM): We use sharded MySQL tables to store our machine translation entries. Sharded tables are a well-established pattern at Etsy, and the system works especially well for handling the large row count needed to accommodate all the text segments. As mentioned earlier, we periodically want to delete older entries in the MTM to clear out unused translations, and make way for improved translations from the translation service. We partition the MTM table by date to accommodate these bulk deletions. Partitioning allows us to drop all the translations from a certain month without worrying about straining system resources or causing lag in our master-master pairs.
-
External Translation Service: If there is new translatable content that doesn’t exist in either our HTM or MTM, we send it to the translation service. Once translated, we store the segment in the MTM so it can be used again later.
- Re-stitching segments: Once each of the segments has passed through one of our four services, we stitch them all back together in the proper order.
The Results
We implemented the Excluder, HTM, and MTM in that order. Implementing the Excluder first allowed us to refine the text splitting, restitching, and monitoring aspects of the pipeline before worrying about data access. Next we built the HTM and populated it with several hundred translations of the most common terms on Etsy. Finally, at the end of November 2015, we began storing and serving translations from the MTM.

Coverage: As you can see from the graphs above, we now only send out 14% of our translations to the translation service, and the rest we can handle internally. Practically, this means we can pre-translate over seven times more text on the same budget. Prior to implementing the translation memory, we pre-translated all non-English listings into English, and a majority of the rest of our listings into French and German. With the translation memory in place, we are pre-translating all eligible listings into English, French, German, Italian, and Japanese, with plans to scale to additional languages.
Quality: Around 1% of our translations (by character count), are now served by the human translation memory. These HTM segments are mostly listing tags. These tags are important for search results and are easily mis-translated by an MT system because they lack the context a human translator can infer more easily. Additionally, human translators are better at conveying the colloquial tone often used by sellers in their listing descriptions. With the HTM in place, the most common paragraph on Etsy, “Thanks for looking!” is human translated into the friendlier, “Merci pour la visite !” rather than the awkward, “Merci pour la recherche !” The English equivalent of this difference would be, “Thanks for visiting!” versus “Thanks for researching!”
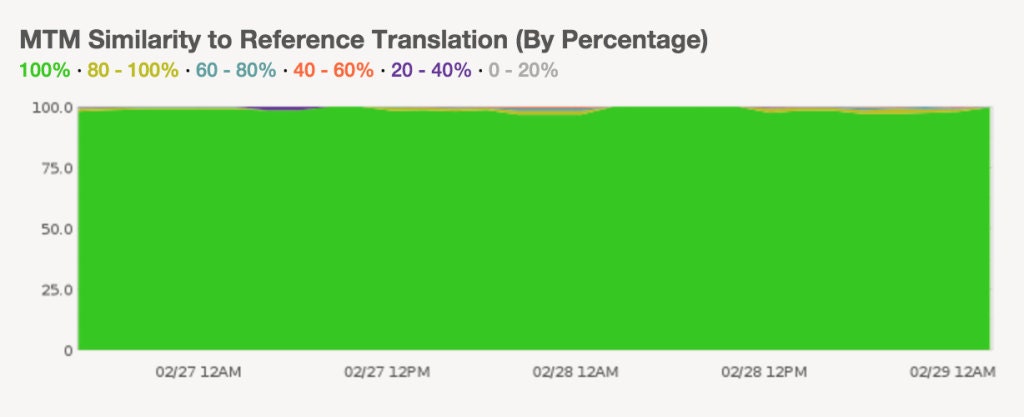
Monitoring: Since a majority of our translation requests are now routed to the MTM rather than the third-party translation service, we monitor our translations to make sure they are sufficiently similar to those served by the translation service. To do this, we sample 0.1% of the translations served from the MTM and send an asynchronous call to the translation service to provide a reference translation of the string. Then we log the similarity (the percentage of characters in common) and Levenshtein distance (also known as edit distance) between the two translations. As shown in the graph below, we track these metrics to ensure the stored MTM translations don’t drift too far from the original third party translations.
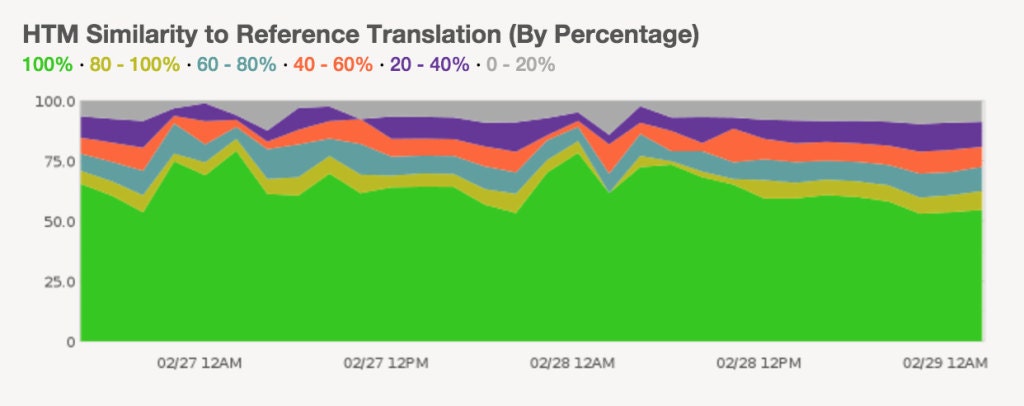
For comparison, as you can see below, the similarity for HTM translations is not as high, reflecting the fact that these translations were not originally drawn from the third party translation service.
Additional Benefits
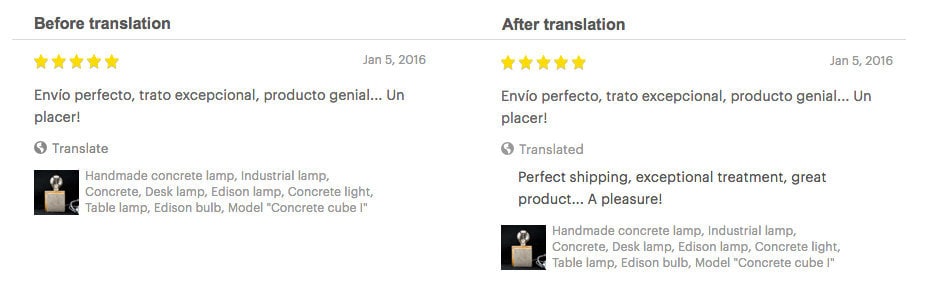
Correcting mis-translations: Machine translation engines are trained on large amounts of data, and sometimes this data contains mistakes. The translation memory gives us more granular control over the translated content we serve, allowing us to override incorrect translations while the translation service we use works on a fix. Below is an example where “Realistic bird” is mis-translated into German as “Islamicrevolutionservice.”

With the translation memory, we can easily correct problematic translations like this by adding an entry to the human translation memory with the original listing title and the correct German translation.
Respecting sellers’ paragraph choices: Handling paragraph splitting ourselves had the additional benefit of improving the quality of translation for many of our listings. Etsy sellers frequently include lists of attributes and other information without punctuation in their listings. For example:
Dimensioni 24x18 cm
Spedizione in una scatola protettiva in legno
Verrà fornito il codice di monitoraggio (tracking code)
The translation service often combines these lists into a single sentence, producing a translation like this:
Size 24 x 18 cm in a Shipping box wooden protective supplies the tracking code (tracking code)
By splitting on paragraphs, our sellers’ choice of where to put line breaks is now always retained in the translated output, generating a more accurate (and visually appealing) translation like this:
Size 24 x 18 cm
Shipping in a protective wooden box
You will be given the tracking code (tracking code)
Splitting on paragraphs prior to sending strings out for translation is an improvement we could have made independent of the translation memory, but it came automatically with the infrastructure needed to build the project.
Conclusion
Greater accuracy for listing translations means buyers can find the items they’re looking for more easily, and sellers’ listings are more faithfully represented when translated. To continue improving quality, over the next month we are rolling out a machine translation engine trained on top of the translation service’s generic engine. A machine translation engine customized with Etsy-specific data, in conjunction with more human translated content, will produce higher-quality translations that more closely reflect the colloquialisms of our sellers.
Building a community-centric, global marketplace is a core tenet of Etsy’s mission. Machine translation is far from perfect, but it can be a valuable tool when fostering an online community built around human interaction. The translation memory allows us to bring this internationalized Etsy experience to more users in more languages, making it easier to connect buyers and sellers from around the world.


