
Targeting Broad Queries in Search

We’ve just launched some big improvements to the treatment of broad queries like “father’s day,” “upcycled,” or “boho chic” on Etsy. This is the most dramatic change to the search experience since our switch to relevance by default in 2011. In this post we’d like to give you an introduction to the product and its development process. We think it’s a great example of the values that are at the heart of product engineering at Etsy: leveraging simple techniques, building iteratively, and understanding impact.
Motivations
Before we make a big investment in an idea, we like to spend some time investigating whether or not that idea represents a reasonable opportunity. The opportunity at the heart of this project is exploratory queries like “silver jewelry” where users don’t have something particular in mind. There are 2.7 MM results for “silver jewelry” on Etsy today. No matter how good we get at ranking results, the universe of silver jewelry is simply so vast that the chances that we will show you something you like are pretty slim. How big of an opportunity is improving the experience for broad queries? How do we even define a broad query? That’s a really difficult question. Going through this exercise can easily turn into doing the hardest parts of the “real work.” Instead of doing something clever, we time-boxed our analysis and looked at a handful of heuristics for different levels of user intent. Here’s a sample:
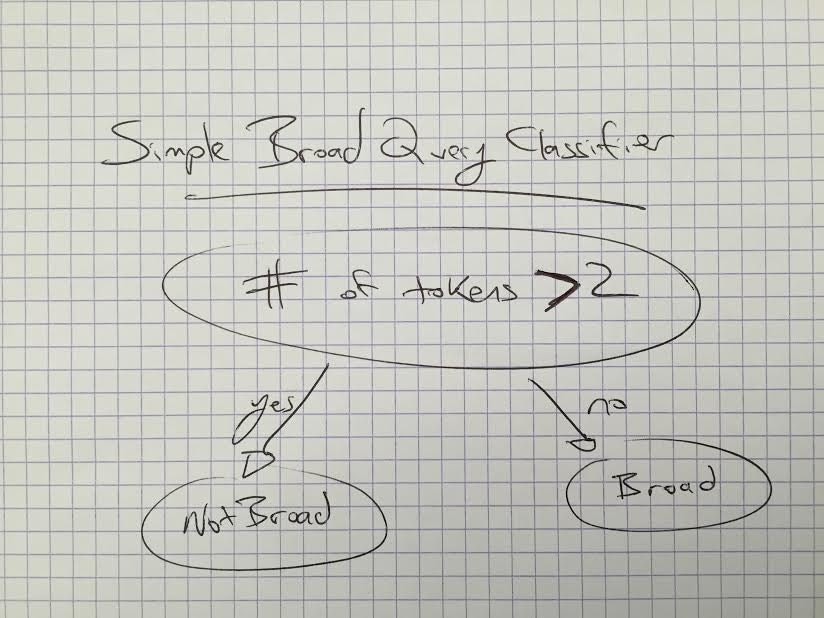
- Number of Tokens
- Result Set Size
- Number of Distinct Categories Represented in the Results
For each heuristic, we looked at the distribution across a week’s worth of search queries, and chose a threshold that generally separated the broad from the specific queries.
We looked at the size of that population and their engagement rates (the green arrow is our target audience):
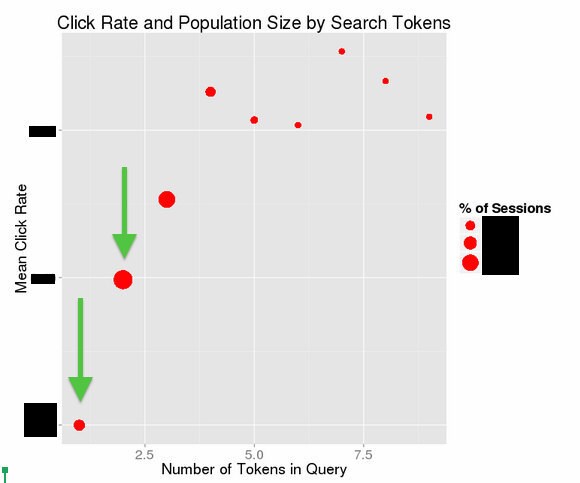
None of the heuristics were independently sufficient, but by looking at several we were able to generate a rough estimate: it turns out that a sizable portion of searches on Etsy are broad queries. That matches our intuitions. Etsy is a marketplace of unique goods so it’s hard for consumers to know precisely what to look for.
Having some evidence that this was a worthwhile endeavor, we packed our bags and set off to meet the wizard.
Crafting an Experience
What can we do to improve the experience for users that issue a broad query? What about grouping the results into discrete buckets so users can get a better sense of what types of things are present? Grouping items into their respective categories seemed like an obvious starting place, but we could also group the items by any number of dimensions like style, color, and material.
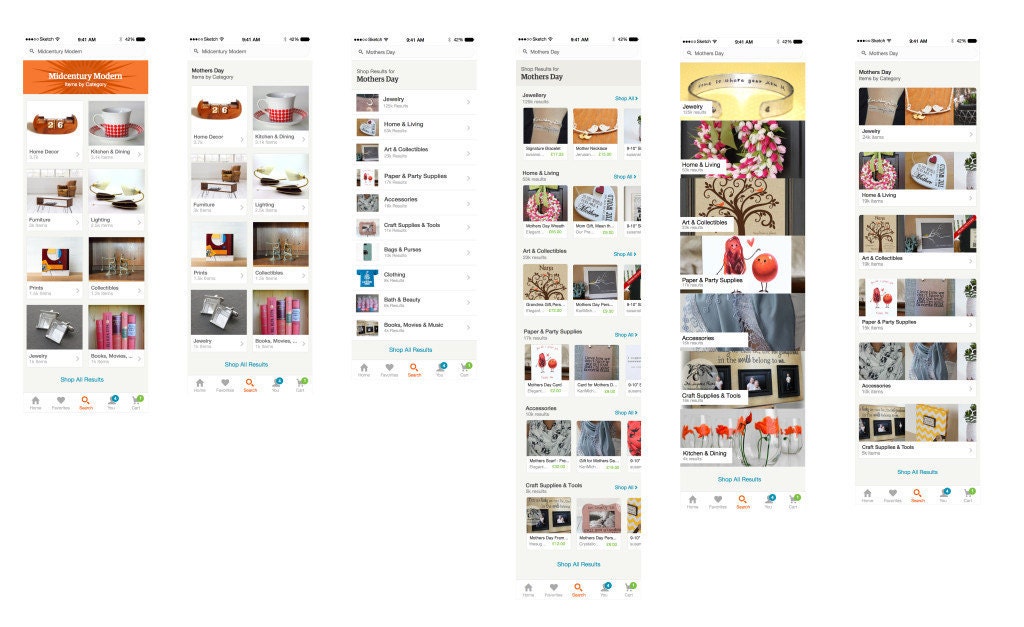
We started with a few quick-and-dirty iterations of design and user-testing. Our designer fashioned a ton of static mocks that he turned into clickable prototypes using Flinto:
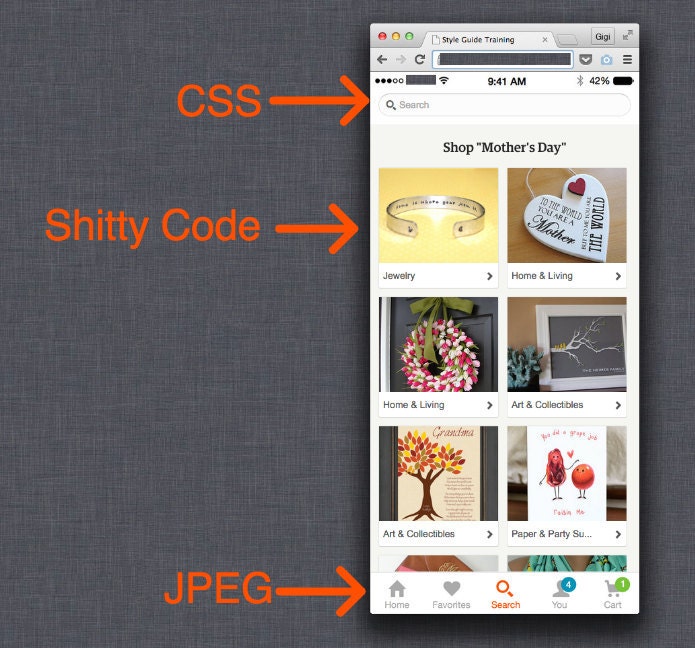
We followed this up with an unshippable prototype of result grouping on mobile web. We did the simplest possible thing: always show result groupings, regardless of how specific the query is. We even simulated a native version using JPEG technology:
People responded really well to these treatments. Many even expressed a desire for the feature before they saw it: “I wish I could just see what types of jewelry there are.”
But the user tests also made it painfully clear how problematic false positives (showing groups when search is definitely not broad) were. There were moments of frustration where users clearly just wanted to see some results and the groups were getting in the way.
On the other hand, showing too many groups didn’t seem as costly. If random or questionably relevant groups appeared towards the end of the list, users often thought they were interesting or highlighted what made Etsy unique (“I didn’t know you had those!”), adding a serendipitous flavor to the experience.
What’s a broad query?
Armed with a binder full of reasonable UX treatments, it was time to start tackling the algorithmic challenge. The heuristics we used at the beginning of this journey were sufficient for ballpark estimation, but they were fairly imprecise and it was clear that minimizing false positives was a priority.
We quickly settled on using entropy, which you can think of as a measure of the uncertainty in a probability distribution. In this case, we’re looking at the probability that a result belongs to a particular category.

As the probabilities get more concentrated around a handful of categories, the entropy approaches zero. For example, this is the probability distribution for the query “shoes” amidst the top-level categories:
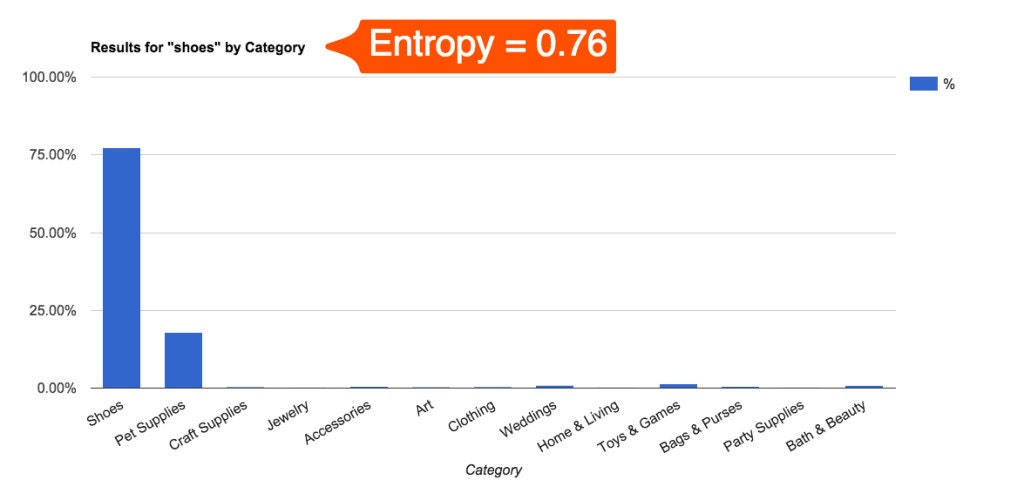
As the distribution gets more dispersed, entropy increases. Here is the same distribution for “father’s day”:
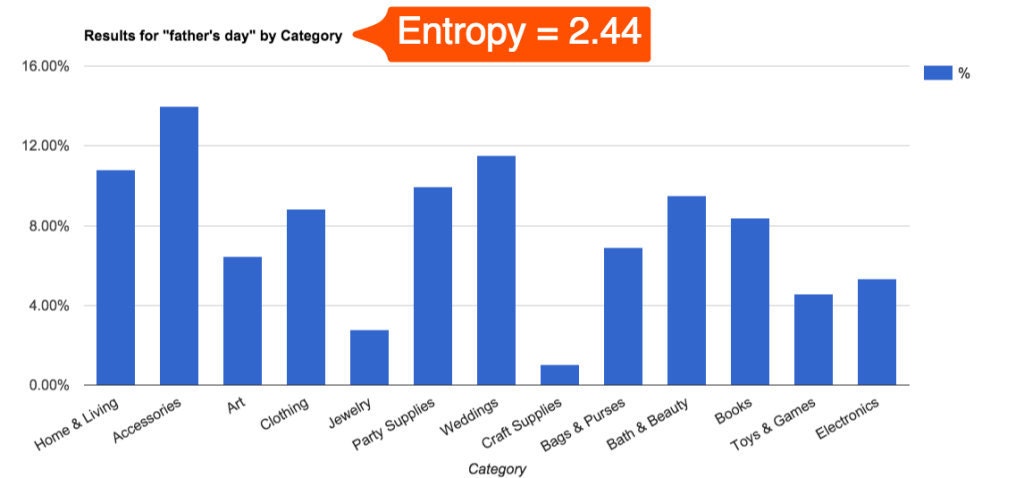
We looked at samples of queries at different entropy levels to manually decide on a reasonable threshold.
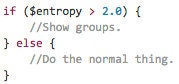
Could we have trained a more sophisticated model with some supervised learning algorithms? Probably, but there are a host of challenges with that approach: getting hand-labeled data or dealing with the noise of using behavioral signals for training data, data sparsity/coverage, etc. Ultimately, we already had what we thought was the most discriminating factor, the resulting algorithm had an intuitive explanation that was easy to reason about, and we felt confident that it would scale to cover the long tail.
Conclusions and Coming Next
After a series of A/B experiments, we’re happy to report that result grouping has resulted in a dramatic increase in user engagement and we’re launching it. But this is only the beginning for this feature and for this story.
Henceforth, result grouping will be another lever in the search product toolbox. The work that we’ve been doing for the past year has really been about building a foundation. We’re going to be aggressively iterating on offline evaluation, new treatments, new grouping dimensions, classification algorithms, and group ordering strategies. We’re in this for the long haul and we’re excited about the many doors this work has opened for us.
I hope this post gave you a taste for what went into this effort. In the coming months, we’re going to have many members of the Etsy Search family diving deeper into some of the meatier details on subjects like result grouping performance, iterating on the entropy-based algorithm, and how our new product categories laid the groundwork for these improvements.
Oh yeah, and we’re hiring.


