
Leveraging Big Data To Create More Secure Web Applications

Here at Etsy, we take measuring things very seriously. We have previously discussed how we harness data to make decisions about software, operations and products, but we have said little about just how useful data can be for the information security practices of a modern web application.
Our Data Team has written several blog articles about how we build, maintain and take advantage of our data infrastructure. Over the years, our data stack has grown to consist of several technologies, including Hadoop and Cascading. At a high level, Cascading leverages Hadoop’s infrastructure while abstracting standard data processing operations, such as splits and joins, away from the underlying mapper and reducer tasks. Cascading allows us to write analytics jobs quickly and easily in a familiar languages (we use both the JRuby and Scala DSL's for Cascading). With a mature Hadoop stack and a multitude of helpful data engineers, the Security Team at Etsy has been taking advantage of the data stack in increasing amounts over the past few months to strengthen our security posture.
Broadly speaking, there are three main types of security practices in which we utilize big data: reactive security mechanisms, proactive security mechanisms, and incident response security practices.
Reactive Security Mechanisms
Reactive security mechanisms usually consist of real-time event monitoring and alerting. These security mechanisms focus on events that trigger immediate responses based on regular information querying: they query the same data and they query it often.
Some examples of reactive security mechanisms at Etsy are automated Splunk searches and anomaly detection based on StatsD/Graphite logs.
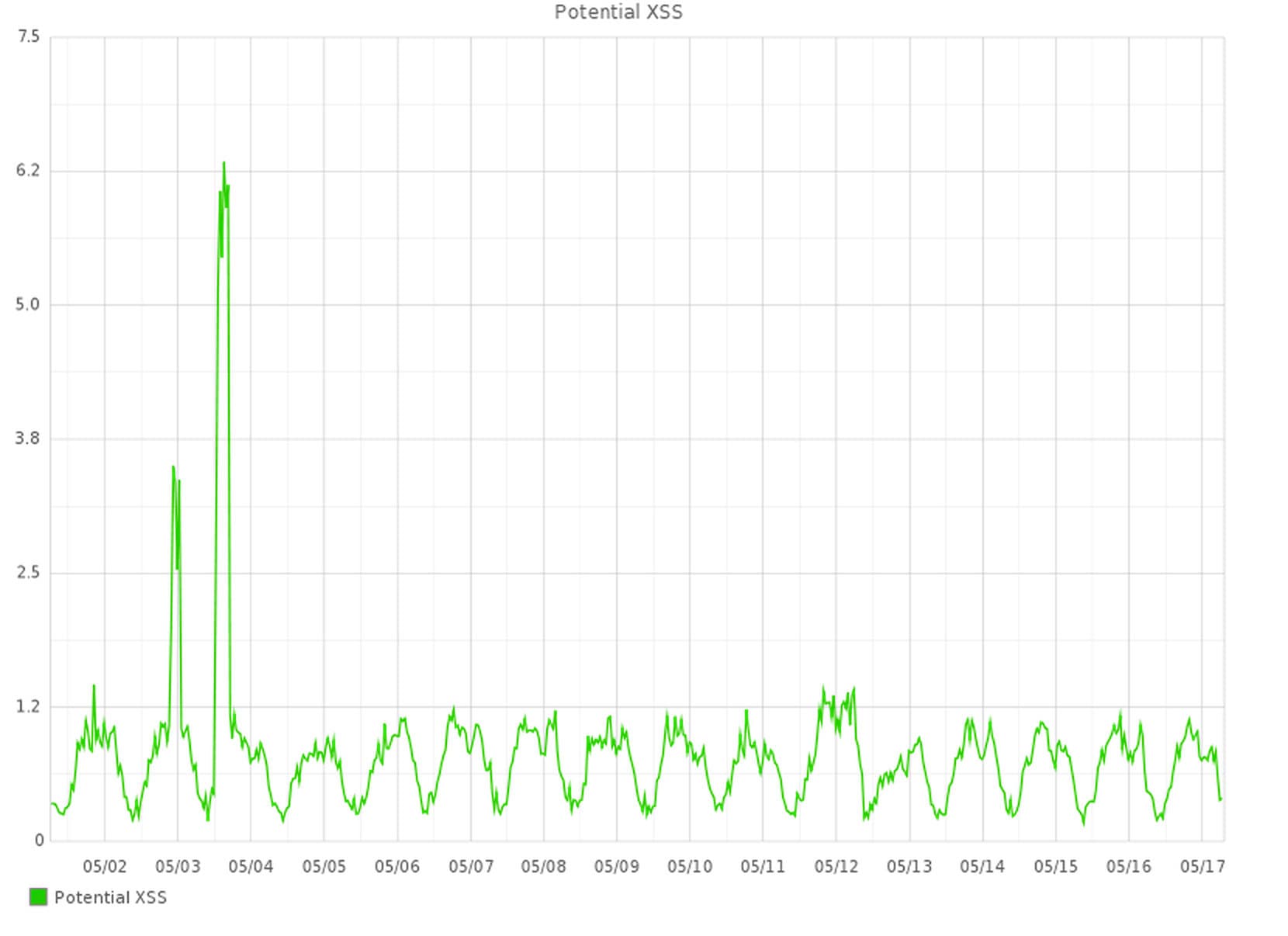
We use saved Splunk searches to identify anomalous patterns in access logs and error logs, such as cross-site scripting and increasing failed log-in rates. These searches typically run once a minute in order to give us a real-time monitoring mechanism. We also built an anomaly detection system based on logs of potentially suspicious events such as failed logins. These two mechanisms are similar with respect to the frequency of data aggregated (constantly) and the frequency of analysis (almost constantly).
As you may guess, reactive security mechanisms cannot be easily implemented in Hadoop. Although Hadoop is fast (isn’t that the point!), the main benefit of using big data infrastructure is to churn through huge quantities of data. For reactive security mechanisms, we want to get as close as possible to real-time results. It wouldn’t be efficient or rational to run this type of analysis on our Hadoop cluster.
Although reactive security mechanisms aren't performed on our cluster, the initial data gathering step is perfectly suited for Hadoop. Figuring out where the thresholds lie for certain metrics by performing predictive analytics and forecasting on past data is a fantastic way to save time that would previously have been spent over several weeks fine-tuning Splunk queries.
Proactive Security Mechanisms
Proactive security mechanisms seek to reduce attack surface or eliminate entire vulnerability classes. This category includes mechanisms such as content security policy, output encoding libraries or full-site SSL. These mechanisms are intended to improve the long-term security posture of the application, rather than collect data about an on-going attack.
Similarly to reactive security mechanisms, we can use predictive analytics and forecasting in Hadoop to weigh the value of our proactive security mechanisms. For example, when determining if our load balancers could handle activating full-site SSL for all Etsy sellers, we ran Hadoop jobs that analyzed past traffic of our sellers to figure out how many requests were made by sellers that were not HTTPS. Armed with this data, as well as metrics from our load balancers, we were able to push out full-site SSL for sellers without encountering unexpected capacity issues.
require 'helpers/analytics'
analytics_cascade do
analytics_flow do
analytics_source 'event_logs'
tap_db_snapshot 'users_index'
assembly 'event_logs' do
group_by 'user_id', 'scheme' do
count 'value'
end
end
assembly 'users_index' do
project 'user_id', 'is_seller'
end
assembly 'ssl_traffic' do
project 'user_id', 'is_seller', 'scheme', 'value'
group_by 'is_seller', 'scheme' do
count 'value'
end
end
analytics_sink 'ssl_traffic'
end
endThe Cascading.jruby source code for this task is relatively straightforward.
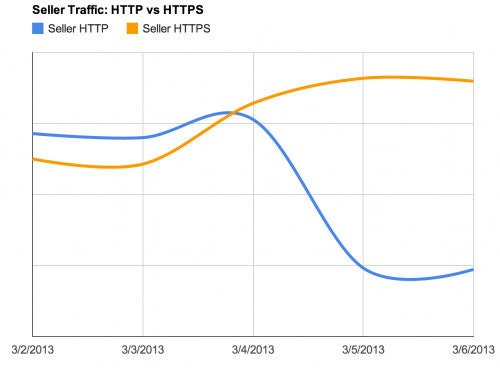
However, unlike reactive security mechanisms, we can use Hadoop to create proactive security mechanisms. The key difference is that these security mechanisms cannot be used to monitor critical metrics that require immediate response or attention. Fortunately, the results of proactive security mechanisms typically don’t require immediate attention. In the SSL example, before we were able to push out full-site SSL for sellers, we had a daily Hadoop job that would break down request patterns to show us which URLs/patterns were requested most often over HTTP. We used this data to iteratively change the scheme of these high value URLs from HTTP to HTTPS while still having data to support the fact that this wouldn’t surpass our restriction on load-balancer terminated SSL connections.
Incident Response
Web application incident response is something that is done often in practice, as it is not limited to responding to full blown compromise. We often need to investigate a threat that has recently targeted organizations that are similar to our own or investigate a new exploit that may affect our technology stack. Typically we are looking for identifying patterns such as URL patterns or IP addresses that have repeatedly accessed our application. Since similar incident response actions are performed frequently, our incident response practices need to be repeatable and, since an incident can occur at any time, we must be able to get the results of our analysis quickly. Even though we want our analysis to be generalizable, it is dependent on the particular threat we are responding to and thus the parameters often need to be changed.
Given all of these conditions, incident response is a perfect example of when to use big data. Incident response is ad-hoc analysis of a large dataset that is driven by an event or incident. We are not going to do it more than once and it needs to be fast. This is a textbook use-case of Hadoop and we take advantage of it constantly for this purpose. Writing template Hadoop jobs that scan our access logs for visits from target IP address or visits to known malicious URL patterns that are easily pluggable with new incident details has proved invaluable to our incident response practices.
Conclusion
The security posture of an application is directly proportional to the amount of information that is known about the application. Big data can be a great source of this kind of information and can be used to gather data to create reactive security mechanisms, gather data to create proactive security mechanisms, directly create new proactive security mechanisms, and to perform incident response.
Although the advantages of analytics from a data science perspective are well-known and well documented, the advantages of analytics from a security perspective have not been explored in-depth. We have found big data to be extraordinarily useful in both creating reactive and proactive security mechanisms, as well as to aiding in incident response. We hope that this will help other organizations in using their data and analytics capabilities more effectively.
Want to know more about how Etsy uses Hadoop to create a more secure web application? The authors of this blog post (Mike Arpaia & Kyle Barry) will be presenting a more in-depth discussion of this topic at the upcoming Black Hat USA conference and Nordic Security Conference. If this has been of interest we hope you'll get a chance to check out our presentations.
You can follow Mike on Twitter at @mikearpaia and you can follow Kyle on Twitter at @allofmywats.


