
Turbocharging Solr Index Replication with BitTorrent

Note: In 2020 we updated this post to adopt more inclusive language. Going forward, we'll use "primary/replica" in our Code as Craft entries.
Many of you probably use BitTorrent to download your favorite ebooks, MP3s, and movies. At Etsy, we use BitTorrent in our production systems for search replication.
Search at Etsy
Search at Etsy has grown significantly over the years. In January of 2009 we started using Solr for search. We used the standard primary-replica configuration for our search servers with replication.
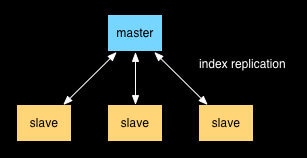
All of the changes to the search index are written to the primary server. The replicas are read-only copies of the primary which serve production traffic. The search index is replicated by copying files from the primary server to the replica servers. The replica servers poll the primary server for updates, and when there are changes to the search index the replica servers will download the changes via HTTP. Our search indexes have grown from 2 GB to over 28 GB over the past 2 years, and copying the index from the primary to the replica nodes became a problem.
The Index Replication Issue
To keep all of the searches on our site working fast we optimize our indexes nightly. Index optimization creates a completely new copy of the index. As we added new boxes we started to notice a disturbing trend: Solr's HTTP replication was taking longer and longer to replicate after our nightly index optimization.
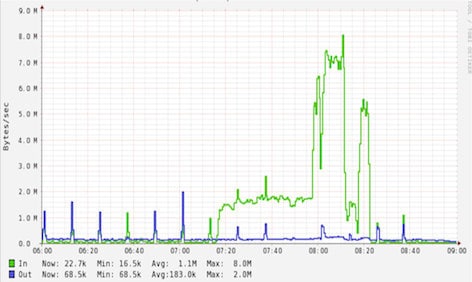
After some benchmarking we determined that Solr's HTTP replication was only allowing us to transfer between 2 MB and 8 MB of data per second. We tried various tweaks to HTTP replication adjusting compression and chunk size, but nothing helped. This problem was only going to get worse as we scaled search. When deploying a new replica server we experienced similar issues, only 8 MB per second transfer pulling all of our indexes at once and it could take over 4 hours, with our 3 large indexes consuming most of the transfer time.
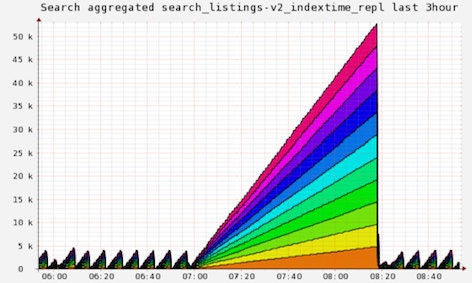
Our 4 GB optimized listings index was taking over an hour to replicate to 11 search replicas. Even if we made HTTP replication go faster, we were still bound by our server's network interface card. We tested netcat from the primary to a replica server and the results were as expected, the network interface was flooded. The problem had to be related to Solr's HTTP replication.
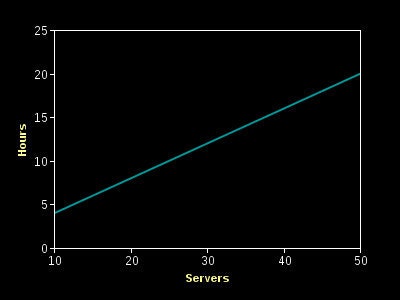
The fundamental limitation with HTTP replication is that replication time increases linearly with the number of replicas. The primary must talk to each replica separately, instead of all at once. If 10 boxes take 4 hours, scaling to 40 boxes would take over half a day!
We started looking around for a better way to gets bits across our network.
Multicast Rsync?
If we need to get the same bits to all of the boxes, why not send the index via multicast to the replicas? It sure would be nice to only send the data once. We found an implementation of rsync which used multicast UDP to transfer the bits. The mrsync tool looked very promising: we could transfer the entire index in our development environment in under 3 minutes. So we thought we would give it a shot in production.
[15:25] patrick: i'm gonna test multi-rsyncing some indexes
from host1 to host2 and host3 in prod. I'll be watching the
graphs and what not, but let me know if you see anything
funky with the network
[15:26] ok
....
[15:31] is the site down?
Multicast rsync caused an epic failure for our network, killing the entire site for several minutes. The multicast traffic saturated the CPU on our core switches causing all of Etsy to be unreachable.
BitTorrent?
For those folks who have never heard of BitTorrent, it's a peer-to-peer file sharing protocol used for transferring data across Internet. BitTorrent is a very popular protocol for transferring large files. It's been estimated that 43% to 70% of all Internet traffic is BitTorrent peer-to-peer sharing.
Our Ops team started experimenting with a BitTorrent package herd, which sits on top of BitTornado. Using herd they transferred our largest search index in 15 minutes. They spent 8 hours tweaking all the variables and making the transfer faster and faster. Using pigz for compression and herd for transfer, they cut the replication time for the biggest index from 60 minutes to just 6 minutes!
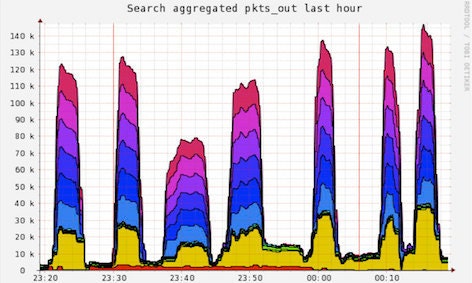
Our Ops experiments were great for the one time each day when we need to get the index out to all the replica servers, but it would also require coordination with Solr's HTTP replication. We would need to stop replication, stop indexing, and run an external process to push the index out to the boxes.
BitTorrent and Solr Together
By integrating BitTorrent protocol into Solr we could replace HTTP replication. BitTorrent supports updating and continuation of downloads, which works well for incremental index updates. When we use BitTorrent for replication, all of the replica servers seed index files allowing us to bring up new replicas (or update stale replicas) very quickly.
Selecting a BitTorrent Library
We looked into various Java implementations of the BitTorrent protocol and unfortunately none of these fit our needs:
- The BitTorrent component of Vuze was very hard to extract from their code base
- torrent4j was largely incomplete and not usable
- Snark is old, and unfortunately unstable
- bitext was also unstable, and extremely slow
Eventually we came upon ttorrent which fit most of the requirements that we had for integrating BitTorrent into the Solr stack.
We needed to make a few changes to ttorrent to handle Solr indexes. We added support for multi-file torrents, which allowed us to hash and replicate the index files in place. We also fixed some issues with large file (> 2 GB) support. All of these changes can be found our fork of the ttorrent code; most of these changes have already been merged back to the main project.
How it Works
BitTorrent replication relies on Lucene to give us the names of the files that need to be replicated.
When a commit occurs the steps taken on the primary server are as follows:
- All index files are hashed, a Torrent file is created and written to disk.
- The Torrent is loaded into the BitTorrent tracker on the primary Solr server.
- Any other Torrents being tracked are stopped to ensure that we only replicate the latest version of the index.
- All of the replicas are then notified that a new version of the index is available.
- The primary server then launches a BitTorrent client locally which seeds the index.
Once a replica server has been notified of a new version of the index, or the replica polls the primary server and finds a newer version of the index, the steps taken on the replica servers are as follows:
- The replica server requests the latest version number from the primary server.
- The Torrent file for the latest index is downloaded from primary over HTTP.
- All of the current index files are hash verified based on the contents of the Torrent file.
- The missing parts of the index are downloaded using the BitTorrent protocol.
- The replica server then issues a commit to bring the new index online.
When new files need to be downloaded, partial (".part") files are created. This allows for us to continue downloading if replication gets interrupted. After downloading is completed the replica server continues to seed the index via BitTorrent. This is great for bringing on new servers, or updating servers that have been offline for a period of time.
HTTP replication doesn't allow for the transfer of older versions of a given index. This causes issues with some of our static indexes. When we bring up new replicas, Solr creates a blank index whose version is greater than the static index. We either have to optimize the static indexes or force a commit before replication will take place.
With BitTorrent replication all index files are hash verified ensuring replica indexes are consistent with the primary index. It also ensures the index version on the replica servers match the primary server, fixing the static index issue.
User Interface
The HTTP replication UI is very clunky: you must visit each replica to understand which version of the index it has. Its transfer progress is pretty simple, and towards the end of the transfer is misleading because the index is actually being warmed, but the transfer rate keeps changing. Wouldn't it be nice to look in one place and understand what's happening with replication?
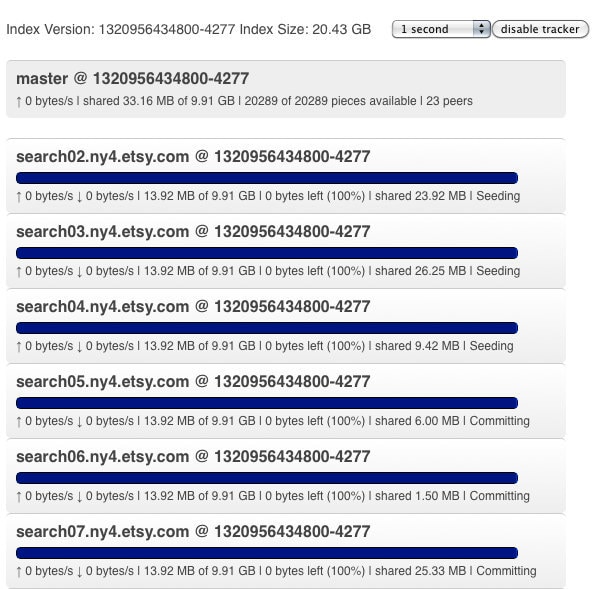
With BitTorrent replication the primary server keeps a list of replicas in memory. The list of replicas is populated by the replicas polling the primary for the index version. By keeping this list we can create an overview of replication across all of the replicas. Not to mention the juicy BitTorrent transfer details and a fancy progress bar to keep you occupied while waiting for bits to flow through the network.
The Results
Pictures are worth a few thousand words. Lets look again at the picture from the start of this post, where we had 11 replica servers pull 4 GB of index.
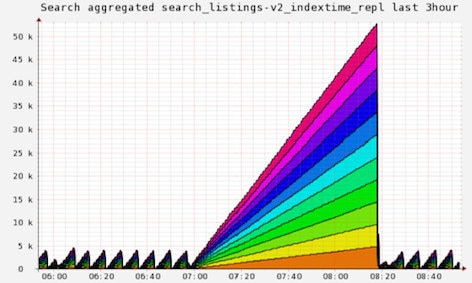
Today we have 23 replica servers pulling 9 GB of indexes.
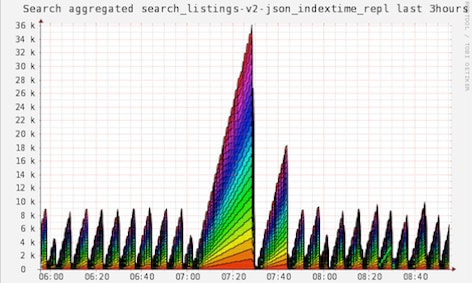
You can see it no longer takes over an hour to get the index out to the replicas despite more than doubling the number of replicas and the index size. The second largest triangle on the graph represents our incremental indexer playing catch up after the index optimization.
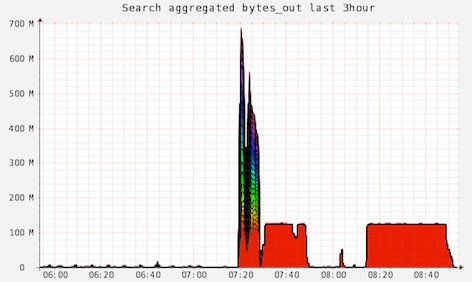
This shows the replicas are helping to share the index as well. The last few red blobs are indexes that haven't been switch to BitTorrent replication.
Drawbacks
One of the BitTorrent features is hash verification of the bits on disk. This creates a side effect when dealing with large indexes. The primary server must hash all of the index files to generate the Torrent file. Once the Torrent file is generated all of the replica servers must compare the hashes to the current set of index files. When hashing 9 GB of index it can take roughly 60 seconds to perform the SHA1 calculations. Java's SHA1 implementation is not thread safe making it impossible to do this process in parallel. This means there is a 2 minute lag before the BitTorrent transfer begins.
To get around this issue we created a thread safe version of SHA1 and a DigestPool interface to allow for parallel hashing. This allows us to tune the lag time before the transfer begins, at the expense of increased CPU usage. It's possible to hash the entire 9 GB in 16 seconds when running in parallel, making the lag to transfer around 32 seconds total.
Improvements
To better deal with the transfer lag we are looking at creating a Torrent file per index segment. Lucene indexes are made up of various segments. Each commit creates an index segment. By creating a new Torrent file per segment we can reduce the lag before transfer to milliseconds, because new segments are generally small.
We are also going to be adding support for transfer of arbitrary files via replication. We use external file fields and custom index time stamp files for keeping track of incremental indexing. It makes sense to have Solr manage replication of these files. We will follow HTTP replication's lead on confFiles, adding dataFiles and indexFiles to handle the rest of the index related files.
Conclusion
Our search infrastructure is mission critical at Etsy. Integrating BitTorrent into Solr allows us to scale search without adding lag, keeping our sellers happy!


