
Translation Memory

As we mentioned in Teaching Etsy to Speak a Second Language, developers need to tag English content so it can be extracted and then translated. Since we are a company with a continuous deployment development process, we do this on a daily basis and as an result get a significant number of new messages to be translated along with changes or deletions of existing ones that have already been translated. Therefore we needed some kind of recollection system to easily reuse or follow the style of existing translations.
A translation memory is an organized collection of text extracted from a source language with one or more matching translations. A translation memory system stores this data and makes it easily accessible to human translators in order to assist with their tasks. There’s a variety of translation memory systems and related standards in the language industry. Yet, the nature of our extracted messages (containing relevant PHP, Smarty, and JavaScript placeholders) and our desire to maintain a translation style curated by a human language manager made us develop an in-house solution.
In short, we needed a system to suggest translations for the extracted messages. Etsy’s Search Team has integrated Lucene/Solr into our deployment infrastructure allowing for Solr configuration, Java-based indexers, and query parsing logic to go to production code in minutes. We decided to take advantage of Lucene’s MoreLikeThis functionality to index “similar” documents, in this case similar English messages with existing translations. The process turned out to be pretty straightforward: we query the requested English message using a ContentStream to the MoreLikeThisHandler and get as a result similar messages with scores. This is done through our Translator's UI via Thrift. We’ve determined a threshold to filter the messages by score in order to only provide relevant translations after getting similar English messages from the query results.
It’s worth mentioning that we need to use a ContentStream to send the source message because most of the time we’ll be requesting translation suggestions for new messages. In other words, messages without translations are not present in our index to match as documents. When sending a ContentSream to the MoreLikeThisHandler, it will extract the "interesting" terms to perform the similarity search.
Here’s a simple diagram of the main parts of this process:
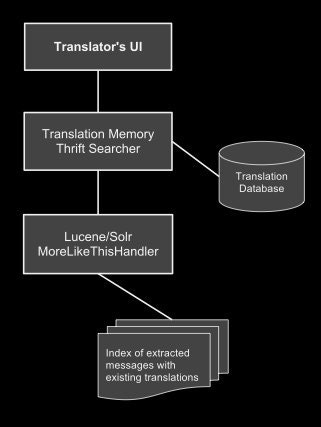
We could easily test and optimize our results on the search environment through Solr queries before wiring the service in the Translator’s UI. As you can see in the following query we send the content (stream.body) of the English message, play with the minimum document frequency (mindf) and term frequency (mintf) of the terms and even filter the query (fq) for translations in a certain language.
http://localhost:8393/solr/translationmemory/mlt?**stream.body=Join%20Now** &mlt.fl=content&**mlt.mindf=1**&**mlt.mintf=1**&mlt.interestingTerms=list &fl=id,md5,content,type,score&fq=**language:de** And since we know you love to read some code, here’s how we defined our translation memory data types and service interface in Thrift:
struct TranslationMemoryResult {
1: string md5
2: double score
}
struct TranslationMemorySearchResults {
1: i32 count,
2: list matchedMessages
}
service TranslationMemorySearch extends fb303.FacebookService {
/**
* Search for translation memory
*
* @param content of the message to match
* @param language code of the existing translations
* @return a TranslationMemorySearchResults instance - never "null"
*/
TranslationMemorySearchResults search(1: string content,
2: i32 type,
3: string language)
}Let’s look at some common use cases where translation memory comes in handy.
It’s pretty common that a new feature is released where we want to attract new members by adding some kind of registration button. In this case the extracted English message has the following data:
Description: A call to action to join etsy.com
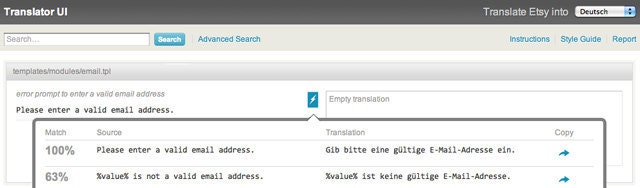
Content: Join NowWhen displaying this message in our Translator’s UI we get the following results after looking for its content in our Translation Memory .
Match Source Translation
100% Join Now Jetzt teilnehmen
80% Join now. It's free! Jetzt anmelden. Kostenlos!Another case is when we have a whole feature translated in the site, but we try some different copy in our English version. In the following example the translators can base their translations in their following suggestions.
Description: Text for when an experimental feature has no requirements
Content: This prototype has no specific requirements. Welcome!
Match Source / Translation
86% This team has no specific requirements. Welcome! / Dieses Team stellt keine speziellen Bedingungen. Willkommen!
86% This experiment has no specific requirements. Welcome! / Für dieses Experiment gibt es keine speziellen Bedingungen. Willkommen!Here’s a screenshot from our Translator’s UI in action:
Having a translation memory system like this has proven to be really useful for our translators who stumble upon new, edited, and deleted messages each day. We also update our index of extracted messages every few minutes with translations, providing resh suggestions.
In addition, we have created a translation glossary manager to maintain a common style when translating. When viewing an English message, we stem the content of the message and match the terms with our glossary. A few examples from our German version of the site are “Search” into “Suche”, “Circles” into “Zirkel”, and “Shop” into –surprisingly, the English word– “Shop”.
So that’s a glimpse of how deal with translations at Etsy. Check back soon for more posts on how we handle internationalization at Etsy.


