
Batch Processing Millions and Millions of Images

I joined Etsy back in February and knew immediately that there would be no shortage of technical challenges. Many of our job postings for Engineering positions describe the company as a place "where the word 'millions' is used frequently and in many contexts". I got a taste of that within my first weeks on the job.
We are in the process of redesigning a few of the major sections around etsy.com. Every item being sold on the site can have up to five photos posted with it. When a seller uploads a new photo, it's resized automatically into six different sizes that are displayed throughout the site. As we redesigned some pages we realized we would need to replace a few of the existing image sizes.
When I started this project, there were 135 million images for items being sold on Etsy, and that number increases every minute as sellers list new items for sale. To provide a sense of scale, let's consider how long it would take me to resize these images by hand in Photoshop. It takes about 40 seconds for me to find and open a file, scale it to a smaller size, and save it to a new location. With a bit of practice, I could probably shave a couple of seconds off of that. But at this rate it would take 170 years to resize all of those images.
But here's the spoiler… We did it in nine days. Every single image.
We spent a number of days laying out this project. We planned for how to move these images to the cloud and resize the whole batch using EC2. We investigated resizing each photo on-demand as it was displayed on the site. Both of these options had drawbacks for us. Instead, we proceeded with what seemed like the simplest approach: batch process the images on our own servers.
Our Weapons of Choice
There are three tools that made up the majority of this project:
GraphicsMagick
If you're not familiar with it, GraphicsMagick is a fork of ImageMagick that has somewhat better performance especially due to its multiprocessor support. Its flexible command-line parameters (almost the same as ImageMagick's) provided good opportunities for performance tuning which I'll talk about shortly.
Perl
It is the "Swiss army knife", right? I didn't use the GraphicsMagick-Perl library, though. All of the resizing tasks were executed as shell commands from the Perl script I wrote. So this really could have been written in any scripting language.
Ganglia
Nearly all of our projects at Etsy include metrics of one sort or another. When testing the resizing process, I saw a decent amount of variability in speeds. By measuring each part of the image conversion process (inspecting original images, copying images to a local ram disk, resizing, comparing to the original, and copying back to the filer), we were able to determine what processes were impacting the overall processing speed. Another benefit to graphing all of this stuff is that with a simple dashboard you can keep everyone in the project up to date with your day-to-day progress.
Tuning GraphicsMagick
GraphicsMagick has a lot of command line options. There is no shortage of dials to turn, and plenty of opportunities for balancing between file size, speed, and quality. I started testing locally on a MacBook Pro, which was ample for working out the quality and file size settings we would use.
Two hundred images from our data set were copied to local disk and used for visual comparisons as we tweaked the settings in GraphicsMagick. Image quality is a very high priority for Etsy and our sellers, so it was difficult to trade off even a small amount of quality for faster rendering or smaller file sizes. I provided test pages of results throughout our benchmarking for internal review -- imagine an HTML page with 200 sample images displayed in rows, with seven columns of varying quality of each image. (Here's a tip for when you do this yourself: don't label the quality settings, the file size, the processing time, or any other data about the images being compared. In fact, don't order the images according to these values. Don't even name the files according to any of these values. Force your judges to make non-biased decisions.)
One option I didn't expect to be fiddling with until we got deep into testing was resampling filters. There are a number of these in GraphicsMagick and you should test and choose one that best suits your needs - speed, file size, and quality. We found seven filters that provided acceptable quality for our images: Blackman, Catrom, Hamming, Hanning, Hermite, Mitchell, and triangle. I tested each of these against our sample set to determine the optimal speed and file size resulting from each filter. Even a few seconds difference in speed when testing 200 images can equate to days, or weeks, when you're processing millions of images.
| Filter | File size (KB) | Time (Sec) |
|---|---|---|
| blackman | 969 | 24 |
| catrom | 978 | 29 |
| hamming | 915 | 24 |
| hanning | 939 | 24 |
| hermite | 937 | 23 |
| mitchell | 922 | 29 |
| triangle | 909 | 23 |
Start with the right image file when you're down-sizing images. We keep full-size original images that are uploaded to the site by our sellers. We cut these into the various image sizes we display on the site. Let's say these sizes are "large," "small," and "extra-small." In this project, we needed to create a "medium" size image and it seemed to make sense that we would want to cut this image directly from the original (full-size) image. We found out, almost by accident, that using the previously down-sized "large" images resulted in better quality and faster processing than starting with the original full-size images.
Compare what you find when tuning performance with a professional. In my case, I went to the source, Bob Freisenhahn, who writes and maintains GraphicsMagick. Bob was kind enough to provide some additional advice that improved performance for this project even more.
Tuning Everything Else
Armed with preliminary testing results, I moved to our production network to test some more under "real world" conditions. There were fairly dramatic differences in the environment, specifically the machine specs and the NFS mounted storage we use for images.
I was expecting CPU to be the bottleneck, but at this point my problem was NFS. With a primed NFS cache, performance can be snappy. But touching un-cached inodes is downright sluggish. I checked out top while running a batch of 10,000 resize operations and saw that the CPU was barely working. I wanted it to be pegged around 95%, but it was chilling out around one percent. When I looked through some Ganglia metrics, it was clear we were bound by NFS seek time. The fastest I was able to process images was five images per second.
Fork to the rescue! I rewrote the portion of the script that handled the read/resize/write operations so that it would be forked from the parent script, which spent its time looping through file names, spawning children, and reaping them when they exited. (When you do this, make it a command-line option so you can tune it easily, e.g. "--max-children=20.") This made a big difference. Lots of NFS seeks could be made in parallel. There were enough processes running that a steady queue built up waiting for NFS to return files from disk, and another queue built up waiting for processor time. Neither spent any time twiddling their thumbs. The resizing speed improved to about 15 images per second. At this rate the total working set would take 2500 hours, or 104 days, to resize. Still not good enough.
Now that we could feed enough images from NFS, we reached for more CPU -- a 16 core (hyperthreaded) Nehalem server. Problem solved, right? Wrong. The resizing speed on this box was actually worse, around 10 images per second. Here's why...
Given the opportunity to use additional processors, GraphicsMagick used all of them. To resize an original image (approx. 1.5 MB) to a thumbnail (approx. 3 KB), GraphicsMagick split up the work across 16 processors, executed each job, and reassembled the results. This was simply too much overhead for the relatively small amount of work actually being done. This can be fixed by tuning the OpenMP threads environment variable when running GraphicsMagick, for example:
env OMP_NUM_THREADS=2 /usr/local/bin/gm ...
This showed an immediate improvement, but I needed to find the sweet spot. I had knobs for both maximum number of children (Perl script) and number of threads (GraphicsMagick) used for resize operations. I ran a number of tests tuning each of these parameters.
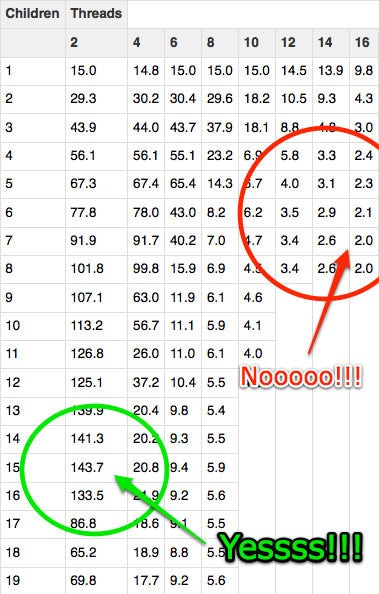
Using two processors per resize operation and running a maximum of 15 children yielded the best results. Note that while tuning these parameters, I tested with local files to exclude variability introduced by NFS. We're now closer to 262 hours (11 days) for the entire working set. This starts to look sufficiently optimized and we can start to simply add some more iron. Four 16-core Nehalems were used for resizing the production working set. This may be the point where you are asking, "who has four of these boxes just lying around?" But if you actually have 135 million images to resize, you probably have some spare hardware around, too.
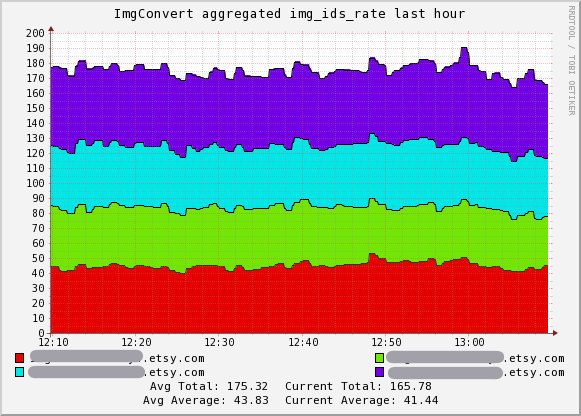
In production, we didn't see the amazing rates of 140 images per second for each machine. We still had to contend with cold seeks across NFS. By applying all of this learning, we managed to get a fairly consistent resize rate for each running machine.
Summary
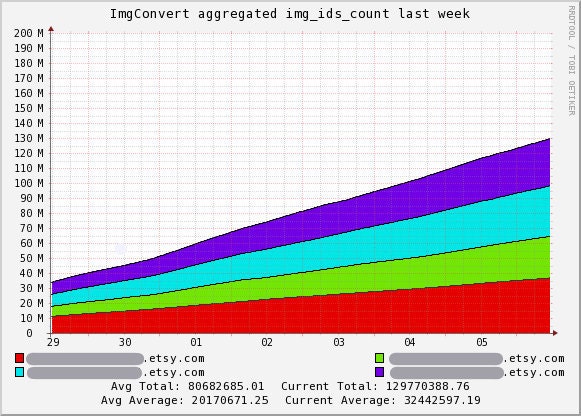
We needed to resize about 135 million images right on our production servers. We accomplished this using GraphicsMagick, Ganglia, Perl, and a very healthy dose of research. In fact, the research phase of this project took longer than the batch processing itself. That was clearly time well spent. This well-tuned resizing process (if you missed the spoiler at the beginning of the article) took only nine days to complete. And since first running the process, we have re-used it two more times on the same data set.
By the way, I can't end this post without also acknowledging our operations team who worked with me and help out on this project. They are amazing. But don't just take my word for it, come find out for yourself.


