
Introducing nagios-herald

Alert design is not a solved problem. And it interests me greatly. What makes for a good alert? Which information is most relevant when a host or service is unavailable? While the answer to those, and other, questions depends on a number of factors (including what the check is monitoring, which systems and services are deemed critical, what defines good performance, etc.), at a minimum, alerts should contain some amount of appropriate context to aid an on-call engineer in diagnosing and resolving an alerting event. When writing Nagios checks, I ask the following questions to help suss out what may be appropriate context:
- How can this alert better define/illustrate what is broken?
- What threshold was met?
- What is the measured value versus the threshold?
- What assumptions were made when the check was written?
- Could exposing those assumptions aid in resolving the issue?
- What things can the operator look into, read, or test to better understand what’s happening?
- Can any of those things be automated or embedded in the alert?
On the last point, about automating work, I believe that computers can, and should, do as much work as possible for us before they have to wake us up. To that end, I'm excited to release nagios-herald today!
nagios-herald: Rub Some Context on It
nagios-herald was created from a desire to supplement an on-call engineer's awareness of conditions surrounding a notifying event. In other words, if a computer is going to page me at 3AM, I expect it to do some work for me to help me understand what's failing. At its core, nagios-herald is a Nagios notification script. The power, however, lies in its ability to add context to Nagios alerts via formatters. One of the best examples of nagios-herald in action is comparing the difference between disk space alerts with and without context.
Disk Space Alert
I've got a vague idea of which volume is problematic but I'd love to know more. For example, did disk space suddenly increase? Or did it grow gradually, only tipping the threshold as my head hit the pillow?
Disk Space Alert, Now with Context!
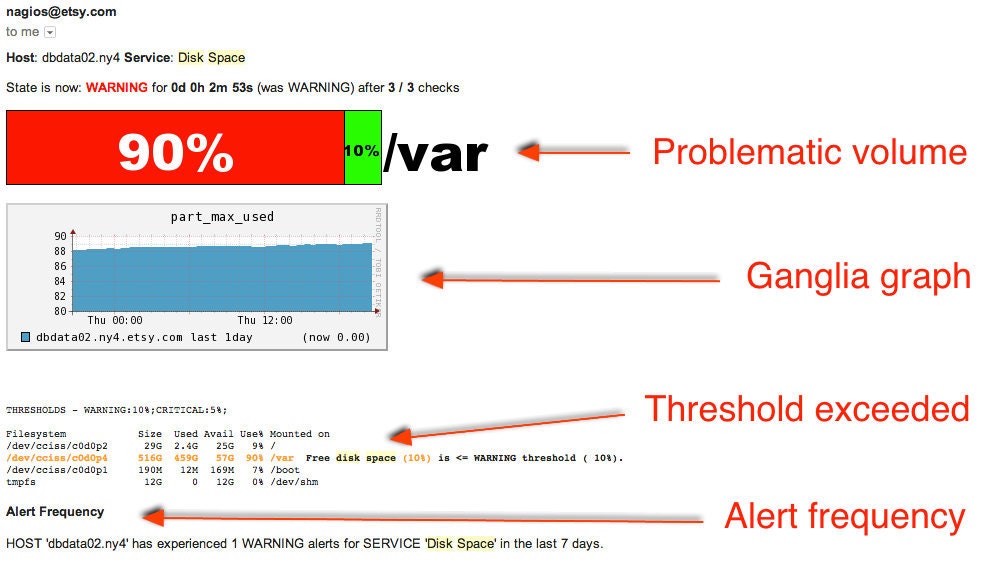
In the example alert above, a stack bar clearly illustrates which volume the alert has fired on. It includes a Ganglia graph showing the gradual increase in disk storage over the last 24 hours. And the output of the df command is highlighted, helping me understand which threshold this check exceeded.
For more examples of nagios-herald adding context, see the example alerts page in the GitHub repo.
"I Have Great Ideas for Formatters!"
I'm willing to bet that at some point, you looked at a Nagios alert and thought to yourself, "Gee, I bet this would be more useful if it had a little more information in it..." Guess what? Now it can! Clone the nagios-herald repo, write your own custom formatters, and configure nagios-herald to load them.
I look forward to feedback from the community and pull requests!
Ryan tweets at @Ryan_Frantz and blogs at ryanfrantz.com


