
Two Sides For Salvation

How do you make changes to your database’s structure that’s getting hammered 24x7 without any disruption? If you use Oracle and paid millions for it, it’s built in. If you use Mysql, it’s one of the holy grails of database operations, and one we’ve learned to do here at Etsy.
Note: In 2020 we updated this post to adopt more inclusive language. Going forward, we'll use "primary/replica" in our Code as Craft entries.
We have a sharded architecture, which means data is scattered across several “shards”. Each shard has different data than all others. Each shard is a primary-primary pair. MM pairs are primaries and replicas at the same time. They not only give you fault tolerance, they divide the read and write load between them that’s impossible to do in the common primary-replica(s) setup. MM pairs have their own set of challenges.
Don’t Let Your Database Generate Anything
The main problem with MM pairs is caused by non-deterministic values generated by the database engine itself, such as autoincrement fields, random numbers and timestamps. The solution to that is that we don’t let the DB generate anything. Every value inserted/modified always comes from the application. This allows us to write to either of the two sides of a MM pair knowing it will get replicated to the other side correctly. I’ve heard that MM pairs don’t make sense since you’re executing everything twice. It’s true that you are executing everything twice, but you’re doing it already if you’re using a primary-replica(s) setup, and the benefits that come from MM pairs are huge. In addition to giving you fault tolerance and load balancing, they are the key to being able to do non-disruptive, live schema changes.
The other part of the puzzle is our shard-aware software layer: our in-house built ORM. It does many different things, but for our current topic, it finds where in our shards a particular object’s data lives. Whenever we need to access the data for an object, the ORM first goes to one of two “index” servers we have, then go to the shard that has the needed data. These index servers are also a MM pair. Index servers get a very large amount of queries, but they are all extremely fast, all in the order of 10-100 microseconds. It’s common for sharded architectures not to have an index server. You simply decide on a sharding scheme when you start, say by user id, then divide the data among your shards knowing where ranges of users live. Everything works great until the number of users on a shard grows beyond what one shard can handle, and by then you’re already in trouble. By having an index server, we can move data between shards and simply update the index to point to the new location.
Our ORM reads a configuration file when it starts, that among other things, contains the list of shard servers available to it. We can add shards as needed with time and add them to the configuration file to start writing data to them, also migrating users so new shards are not idle at first and to balance the load among all shards.
The kicker: when we do schema changes, we take out one server from each of the MM pairs from the configuration file and gracefully restart the application. The ORM re-reads its configuration and knows only about the active shard sides. This leaves the application running on half of our database servers. Nobody notices. We immediately see in our many graphs that one side’s traffic plummets and the other side is taking all the load.
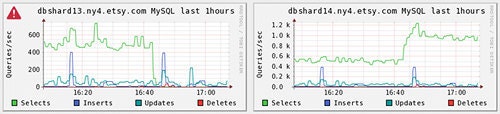
Note that half of the servers does not mean half of the data. All data lives on both sides of a MM pair. Replication is still going both ways, we never break it. The active side simply stops getting inserts/updates/deletes from the inactive side because nothing is connecting to it. But the inactive side still gets inserts/updates/deletes from the active side since it’s still a replica. We could break replication for the ALTERs, but there’s no benefit in doing so and adds an unnecessary step (with the one exception of the session we’re actively doing ALTERs in. We don’t want those to replicate.)
At this point we are ready to make as many changes as we need on the inactive side. In Mysql terms, ALTERs. These ALTERs can take anywhere from minutes to hours to complete and lock the tables they are modifying, but we’re operating on the inactive side and definitely don’t want any of our work to replicate to the other side, so we prepend ALTERs with SET SQL_LOG_BIN=0.
When these alters are done, they have been applied to the inactive side only. Another change in the config file places these servers back into active mode. We wait for load to stabilize between both sides, replication to catch up if it has lagged behind, then we’re ready to repeat for the side that hasn’t been ALTER’ed.
Taking sides out of production is not only useful for schema changes, but for upgrades, configuration changes, and any other necessary downtime.
So this is all great, works well for us. We routinely do schema changes with no user impact. But what if you don’t have an ORM? Mysql Proxy may be your answer. It’s very simple to have web servers connect to a pool of available backend database servers with Mysql Proxy. You can read the documentation for it at Mysql’s website. An important feature of Mysql Proxy is that it allows you to change configuration on-the-fly, so you can take servers in and out without even having to stop or reload your application.
MM pairs have had a bad reputation of being quirky. They can be, but as long as you don’t let your database generate anything, they work. When you need to do frequent schema changes in a 24×7 environment, they are key to no-downtime schema changes.
If you want more details on our database architecture, you can also check here.


