
Divide and Concur

By Noah Sussman and Laura Beth Denker.
Splitting Up A Large Test Suite
Lately we've been deploying code 25 times a day or more, and running automated tests every time we deploy. Conservatively, we run our tests about 25 times on a normal business day.
At Etsy, deployments are managed by engineers, not by ops or a release management team. The idea is: you write code, and then you deploy it to production. Even dogs deploy code. By the time 8am rolls around on a normal business day, 15 or so people and dogs are starting to queue up, all of them expecting to collectively deploy up to 25 changesets before the day is done.

If 15 Engineers Deploy 25 Changesets In 24 Hours...
Deploys generally take about 20 minutes. Any longer than that and the people at the back of the queue can wind up waiting a really long time before they get to deploy. In our world, "a really long time" means you waited two hours or more before you could make a production deployment.
We call the tests that get run before deployment "trunk tests" because they test Etsy's production functionality. There are 7,000 trunk tests, and we're adding more all the time. In truth, we have more tests than that, but we don't run all of them when we deploy (more on that in just a moment).
If the trunk tests fail, deployment pauses while the engineers look for the source of the problem. Usually this takes under 5 minutes and ends with someone sheepishly making a fixing commit. The tests are then re-run, and if they pass, deployment continues.
Through trial-and-error, we've settled on about 11 minutes as the longest that the automated tests can run during a push. That leaves time to re-run the tests once during a deployment, without going too far past the 20 minute time limit.
Run end-to-end, the 7,000 trunk tests would take about half an hour to execute. We split these tests up into subsets, and distribute those onto the 10 machines in our Jenkins cluster, where all the subsets can run concurrently. Splitting up our test suite and running many tests in parallel, gives us the desired 11 minute runtime.
Keep Tests That Are Similar, Together
We decided to use PHPUnit's @group annotations (really just a special form of comments) to logically divide the test suite into different subsets. Jenkins and PHPUnit group annotations turned out to be a simple and powerful combination.
Each PHPUnit job we set up in Jenkins has its own XML configuration file that looks something like this:
< groups>
< include>
< group>dbunit< /group>
< /include>
< exclude>
< group>database< /group>
< group>network< /group>
< group>flaky< /group>
< group>sleep< /group>
< group>slow< /group>
< /exclude>
< /groups>
This particular config block means that this PHPUnit job will run tests tagged as dbunit. And this job will not run tests tagged database, network, flaky, sleep, or slow.
Test Classification: the Good, the Fast and the Intermittent
If you feel like 11 minutes should be enough to run 7,000 unit tests, you're right. But not all of our automated tests are unit tests. Or at least, they're not what we call unit tests. Every shop seems to have its own terminology for describing kinds of tests, and... so do we.
Here's how we classify the different kinds of tests that run in our CI system.
Unit Tests
We define a unit test as a test for one-and-only one class, and that has no database interaction at all, not even fixtures.
You may have noticed above that we didn't define a PHPUnit annotation for unit tests. Unit tests are the default.
We run the unit tests on a server where MySQL and Postgres aren't even available. That way we find out right away if a database dependency was added accidentally.
As of today, we have about 4,500 unit tests, which run in about a minute.
Integration Tests
For the most part when we say a test is an integration test, this implies that the test uses fixtures. Usually our fixtures-backed tests are built with the PHPUnit port of DBUnit. We've even provided some PHPUnit extensions of our own to make testing with DBUnit easier.
We also apply the term "integration tests" to test cases that depend on any external service (eg Memcache or Gearman).
The integration tests are the slowest part of our suite. If we ran them all sequentially, the integration tests alone would take about 20 minutes for every deployment. Instead, we spend about 8 minutes per deploy running them concurrently.
Network Tests
Some integration tests may also access network resources. For instance, a test might assert that our libraries can properly send an email using a third-party service.
For the most part, we try to avoid tests like this. When a test depends on a network request, it can fail just because the request was unsuccessful. That can occur for a number of reasons, one of which may be that the service being tested against is actually down. But you never really know.
Smoke Tests
Smoke tests are system level tests that use Curl.
For the most part, our smoke tests are PHPUnit test cases that execute Curl commands against a running server. As the response from each request comes back, we assert that the proper headers and other data were returned from the server.
Functional Tests
Like smoke tests, end-to-end GUI-driven functional tests are also run against a live server, usually our QA environment (for more on that see the comments). For these tests we use Cucumber and Selenium, driving a Firefox instance that runs in an Xvfb virtual desktop environment.
Since they are very labor-intensive to develop and maintain, end-to-end functional tests are reserved for testing only the most mission-critical parts of Etsy. We get a lot of confidence from running our unit, integration and smoke tests. But at the end of the day, it's good to know that the site is so easy to use, even a robot user agent can do it.
Zero Tolerance for Intermittent Tests
Sometimes tests fail for no good reason. It's no big deal, it happens. A test can be a bit flaky and still be helpful during development. And such tests can be useful to keep around for reference during maintenance.

But running tests before deployment is different than running tests during maintenance or development. A test that only fails 2% of the time will fail about every other day if run before each of our 25 deployments. That's 2-3 failures a week. And in practice each failure of the trunk tests translates to around 10 minutes of lost developer time -- for every developer currently waiting to make a deployment!
So a single test that fails only 2% of the time can easily incur a cost of about 5 wasted work-hours per week. We therefore provide a few other PHPUnit group annotations which anyone is free to use when they encounter a test that isn't quite robust enough to block deployment.
Intermittent Tests
We use the annotation @group flaky to denote a test that has been observed to fail intermittently. Tests so annotated are automatically excluded from running during deployment.
This has worked out better for us than skipping or commenting out intermittent tests. Tests annotated as flaky can still be run (and are still useful) in some contexts.
Slow Tests
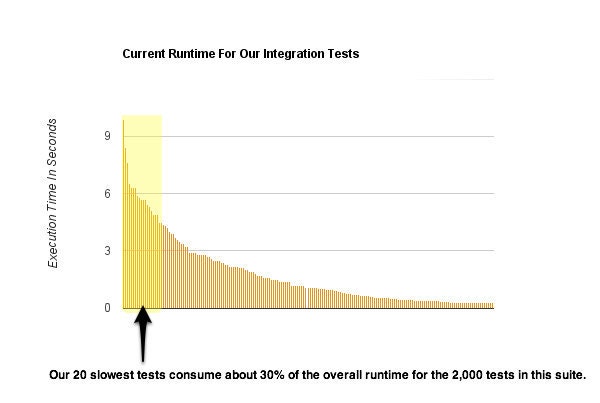
Observation has repeatedly shown that our slowest tests roughly exhibit a power law distribution: a very few tests account for a great deal of the overall runtime of the test suite.
Periodically we ask that engineers identify very long-running tests and tag them as @group slow. Identifying and "retiring" our top 20 slowest tests (out of 7,000) usually results in a noticeable speedup of the test suite overall.
Again, tests so annotated may still be run (and are still useful) in some contexts, just not before deployment.
Sleep Tests and Time Tests
Good tests don't sleep() nor do they depend on the system clock.
Sometimes getting test coverage at all means writing less-than-good tests (this is especially true when writing new tests for legacy code). We accept this reality -- but we still don't run such tests before deployment.
Fast, Reliable Tests
Our CI system is still relatively new (most tests are under two years old and the Jenkins instance only dates back to July) so we still have a lot of work to do in terms of building awesome dashboards. And in the future we'd like to harvest more realtime data from both the tests, and from Jenkins itself.
But so far we've been very happy with the CI system that has resulted from using PHPUnit annotations to identify subsets of functionally similar tests and running the subsets concurrently on a cluster of servers. This strategy has enabled us to quadruple the speed of our deployment pipeline and given us fine-grained control over which tests are run before each of our 25 or more daily deploys. It's a lightweight process that empowers anyone who knows how to write a comment to have input into how tests are run on Etsy's deployment pipeline.


