
Tracking Every Release

We spend a lot of time gathering metrics for our network, servers, and many things going on within the code that drives Etsy. It's no secret that this is one of our keys to moving fast. We use a variety of monitoring tools to help us correlate issues across our architecture. But what most monitoring tools achieve is correlating the effects of change, rather than the causes.
Change to application code (deploys) are opportunities for failure. Tweaking pages and features on your web site cause ripples throughout the metrics you monitor, including database load, cache requests, web server requests, and outgoing bandwidth. When you break something on your site, those metrics will typically start to skew up or down.

Something obviously happened here… but what was it? We might correlate this sudden spike in PHP warnings with a drop in member logins or a drop in traffic on our web servers, but these point to effects and not to a root cause.
We need to track changes that we make to the system.
Different companies track change in ways that are reflective of their release cycle. A company that only releases new software or services once or twice a year might literally do this by distributing of a press release. Companies that move more quickly and release new products every few weeks might rely on company-wide emails to track changes. The faster the iteration schedule, the smaller and less formal the announcement becomes.
When you reach the point of releasing changes a couple of times a day, this needs to be automated and needs to be distributed to places where it is quickly accessible, such as your monitoring tools and IRC channels. At Etsy, we are releasing changes to code and application configs over 25 times a day. When the system metrics we monitor start to skew we need to be able to immediately identify whether this is a human-induced change (application code) or not (hardware failure, third-party APIs, etc.). We do this by tracking the time of every single change we ship to our production servers.
We've been using Graphite for monitoring application-level metrics for nearly a year now. These include things like numbers of new registrations, shopping carts, items sold, image uploaded, forum posts, and application errors. Getting metrics into Graphite is simple, you send a metric name, a value, and the current Unix timestamp. To track time-based events, the value sent for the metric can simply be "1". Erik Kastner added this right into our code deployment tool so that every single deploy is automatically tracked. You didn't think we did this by hand, did you?
events.deploy.website 1 1287106599
The trick to displaying events in Graphite is to apply the drawAsInfinite() function. This displays events as a vertical line at the time of the event. (Hat tip: Mark Lin, since this is not well documented.) The result looks like this:
http://graphite.example.com/render/ ?target=drawAsInfinite%28events.deploy.website%29 &from=-24hours
Graphite has a wonderfully flexible URL API that allows for mixing together multiple data sets in a single graph. We can mix our code deployments right into the graph of PHP warnings we saw above.

Ah-ha! A code change occurred right after 4 PM that set off the warnings. And you can see that a second deploy was made about 10 minutes later that fixed most of the warnings, and a third deploy that squashed anything remaining.
We maintain a battery of thousands of tests that run against our application code before every single deploy, and we're adding more every day. Combined with engineers pairing up for code reviews, we catch most issues before they get deployed. Tracking every deploy allows us to quickly detect any bugs that we missed.
Equally useful is the reassurance we have that we can deploy many times a day without disrupting core functionality on the site. Across the 16 code deploys shown below, not a single one caused an unexpected blip in our member logins.

These tools highlight the good events along with the bad. Ian Malpass, who works on our customer support tools, uses Graphite to monitor the number of new posts written in our forums, where Etsy members discuss selling, share tips, report bugs, and ask for help. When we correlate these with deploys, you can see the flurry of excitement in our forums after one of our recent product launches.
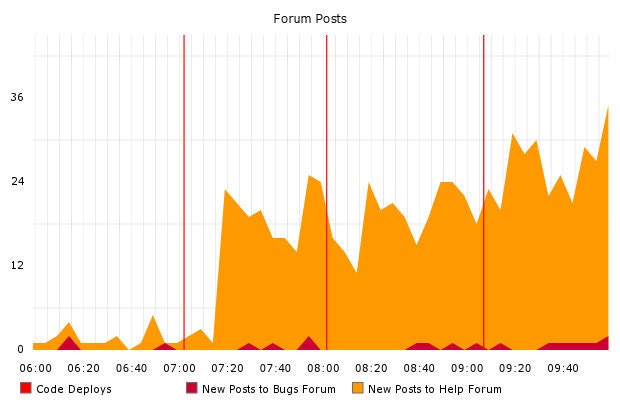
Automated tracking of code deploys is essential for teams who practice Continuous Deployment. Monitoring every aspect of your server and network architecture helps detect when something has gone awry. Correlating the times of each and every code deploy helps to quickly identify human-triggered problems and greatly cut down on your time to resolve them.


